
Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
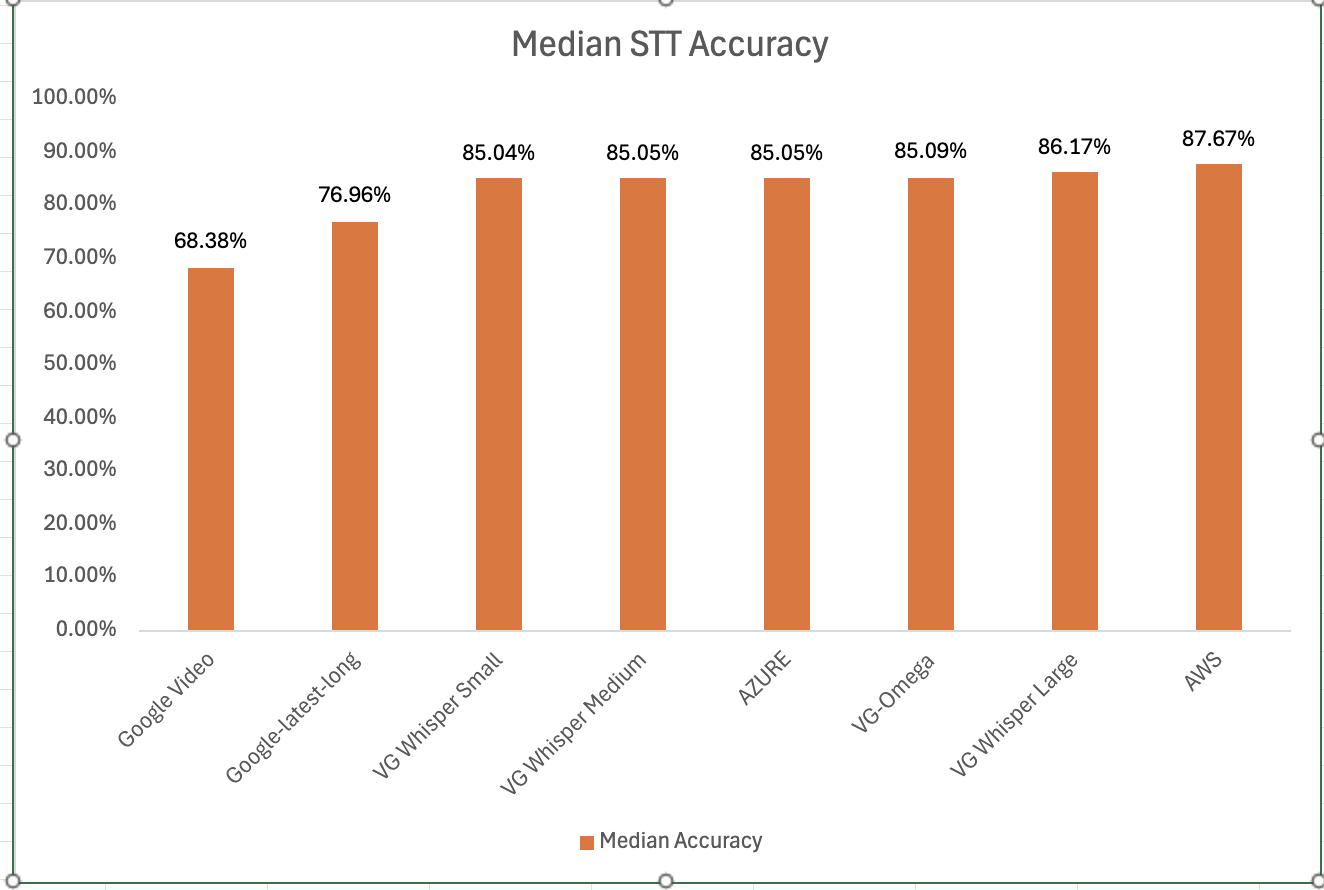
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

On March 1st 2023, Open AI announced that developers could access the Open AI Whisper Speech-to-Text model via easy-to-use REST APIs. OpenAI also released APIs to GPT3.5, the LLM behind the buzzy ChatGPT product. General availability of the next version of LLM - GPT 4 is expected in July 2023.
Since Open AI Whisper's initial release in October 2022, it has been a big draw for developers. A highly accurate open-source ASR is extremely compelling. OpenAI's Whisper has been trained on 680,000 hours of audio data which is much more than what most models are trained on. Here is a link to their github.
However the developer community looking to leverage Whisper faces three major limitations:
1. Infrastructure Costs: Running Whisper - especially the large and medium models - requires expensive memory-intensive GPU based compute options (see below).
2. In-house AI expertise: To use Open AI's Whisper model, a company has to invest in building an in-house ML engineering team that is able to operate, optimize and support Whisper in a production environment. While Whisper provides core features like Speech-to-Text, language identification, punctuation and formatting, there are still some missing AI features like speaker diarization and PII redaction that would need to be developed. In addition, companies would need to put in place a real-time NOC for ongoing support. Even a small scale 2-3 person developer team could be expensive to hire and maintain - unless the call volumes justify such an investment. This in-house team also needs to take full responsibility for the Cloud infrastructure related tasks like auto-scaling and log monitoring to ensure uptime.
3. Lack of support for real-time: Whisper is a batch speech-to-text model. For developers requiring streaming Speech-to-Text models, they need to evaluate other ASR/STT options.
By now taking over the responsibility of hosting this model and making it accessible via easy-to-use APIs, both Open AI and Voicegain addresses the first two limitations.
Aug 2023 Update: On Aug 5th 2023, Voicegain announced the release Voicegain Whisper, an optimized version of Open AI's Whisper using Voicegain APIs. Here is a link to the announcement. In addition to Voicegain Whisper, Voicegain also offer realtime/streaming Speech-to-Text and other features like two-channel/stereo support (required for call centers), speaker diarization and PII redaction. All of this is offered in Voicegain's PCI and SOC-2 compliant infrastructure.
This article highlights some of the key strengths and limitations of using Whisper - whether using Open AI's APIs, Voicegain APIs or hosting it on your own.
In our benchmark tests, OpenAI's Whisper models demonstrated high accuracy for a widely diverse range of audio datasets. Our ML engineers concluded that the Whisper models perform well on audio datasets ranging from meetings, podcasts, classroom lectures, YouTube videos and call center audio. We benchmarked Whisper-base, Whisper-small and Whisper-medium against some of the best ASR/Speech-to-Text engines in the market.
The median Word Error Rate (WER) for Whisper-medium was 11.46% for meeting audio and 17.7% for call center audio. This was indeed lower than the WERs of STT offerings of other large players like Microsoft Azure and Google. We did find that AWS Transcribe had a WER that is competitive with Whisper.
Here is an interesting observation - it is possible to exceed Whisper's recognition accuracy, however it would take building custom models. Custom models are models that are trained on our client's specific audio data. In fact for call center audio, our ML Engineers were able to demonstrate that our call-center specific Speech-to-text models were either equal to or even better than some of the Whisper models. This makes intuitive sense because call center audio is not readily available on the internet for Open AI to get access to.
Please contact us via email (support@voicegain.ai) if you would like to review and validate/test these accuracy benchmarks.
Whisper's pricing at $0.006/min ($0.36/hour) is much lower than the Speech-to-Text offerings of some of the other larger cloud players. This translates to a 75% discount to Google Speech-to-Text and AWS Transcribe (based on pricing as of the date of this post).
Aug 2023 Update: At the launch of Voicegain Whisper, Voicegain announced a list price at $0.0037/min ($0.225/hour). This price is 37.5% lower than Open AI's price and has been accomplished since we optimized the throughput of Whisper. To test it out, please sign up for a free developer account. Instructions are provided here.
What was also significant was Open AI announced the release of ChatGPT APIs with the release of Whisper APIs. Developers can combine the power of Whisper Speech-to-Text models with the GPT 3.5 and GPT 4.0 LLM (the underlying model that ChatGPT uses) to power very interesting conversational AI apps. However here is an important consideration - Using Whisper API with LLMs like ChatGPT works as long as the app only uses batch/pre-recorded audio (e.g analyzing recording of call center conversations for QA or Compliance or transcribe and mine Zoom meetings to recollect context). For developers looking to build Voice Bots or Speech IVRs, they would need a good real-time Speech-to-Text model.
As stated above, Open AI's Whisper does not support apps that require real-time/streaming transcription - this could be relevant to a wide variety of AI apps that target call center, education, legal and meetings use-case. In case you are looking for a streaming Speech-to-Text API provider, please feel free to contact us with the email address provided below
The throughput of Whisper models - both for the medium and large models - is relatively low. At Voicegain, our ML engineers have tested the throughput of Whisper models on several popular NVIDIA GPU-based compute instances available in public clouds (AWS, GCP, Microsoft Azure and Oracle Cloud). We also have real-life experience because we process over 10 million hours of audio annually. As a result, we have a strong understanding of what it takes to run a model like OpenAI's Whisper in a production environment.
We have found out that the infrastructure cost of running Whisper-medium in a cloud environment is in the range of $0.07 - $0.10/hour. You can contact us via email to get the in-depth assumptions and backup behind our cost model. An important factor to note is that in a single-tenant production environment the compute infrastructure cannot be run at a very high utilization. The peak throughput required to support real-life traffic can be several times (2-3x) the average throughput. Net-net, we determined that while developers would not have to pay for software licensing, the cloud infrastructure costs would still remain substantial.
In addition to this infrastructure cost the larger expense of running Whisper on the Edge (On-Premise + Private Cloud) is that it would require a dedicated back-end Engineering & Devops team that can chop the audio recording into segments that can be submitted to Whisper and perform the queue management. This team would need to also oversee all info-sec and compliance needs (e.g. running vulnerability scans, intrusion detection etc).
As of the publication of this post, Whisper does not have a multi-channel audio API. So if your application involves audio with multiple speakers, then Whisper's effective price-per-min = Number of channels * 0.006. For both meetings and call center use-cases, this pricing can become prohibitive.
This release of Whisper is missing some key features that developers would need. The three important features we noticed are Diarization (speaker separation), Time-stamps and PII Redaction.
Voicegain is working on releasing a Voicegain-Whisper Model over its APIs. With this developers can get benefits of Voicegain PCI/SOC-2 compliant infrastructure and advanced features like diarization, PII redaction, PCI compliance and time-stamps. To join the waitlist, please email us at sales@voicegain.ai
At Voicegain, we build deep-learning-based Speech-to-Text/ASR models that match or exceed the accuracy of STT models from the large players. For over 4 years now, startup and enterprise customers have used our APIs to build and launch successful products that process over 600 million minutes annually. We focus on developers that need high accuracy (achieved by training custom acoustic models) and deployment in private infrastructure at an affordable price. We provide an accuracy SLA where we guarantee that a custom model that is trained on your data will be as accurate if not more than most popular options including Open AI's Whisper.
We also have models that are trained specifically on call center audio. While Whisper is a worthy competitor (of course a much larger company with 100x our resources), as developers we welcome the innovation that Open AI is unleashing in this market. By adding ChatGPT APIs to our Speech-to-Text , we are planning to broaden our API offerings to developer community.
To sign up for a developer account on Voicegain with free credits, click here.

Like Voicegain Transcribe, there are other cloud-based Meeting AI and AI note-taking solutions that work with video meeting platforms like Zoom and Microsoft Teams. However they do not meet the requirements of privacy-sensitive enterprise customers in financial services, healthcare, manufacturing and high-tech and other industry verticals. Data privacy and control issues would mean that these customers would want to deploy an AI based meeting assistant in their private infrastructure behind their corporate firewall.
Voicegain Transcribe has been designed and developed for the On-Prem Datacenter or Virtual Private Cloud use-case. Voicegain has already deployed this at a large global Fortune 50 company, making it one of the first truly On-premise/private-cloud AI Meeting Assistant solutions in the market.
The key features of Voicegain Transcribe are:
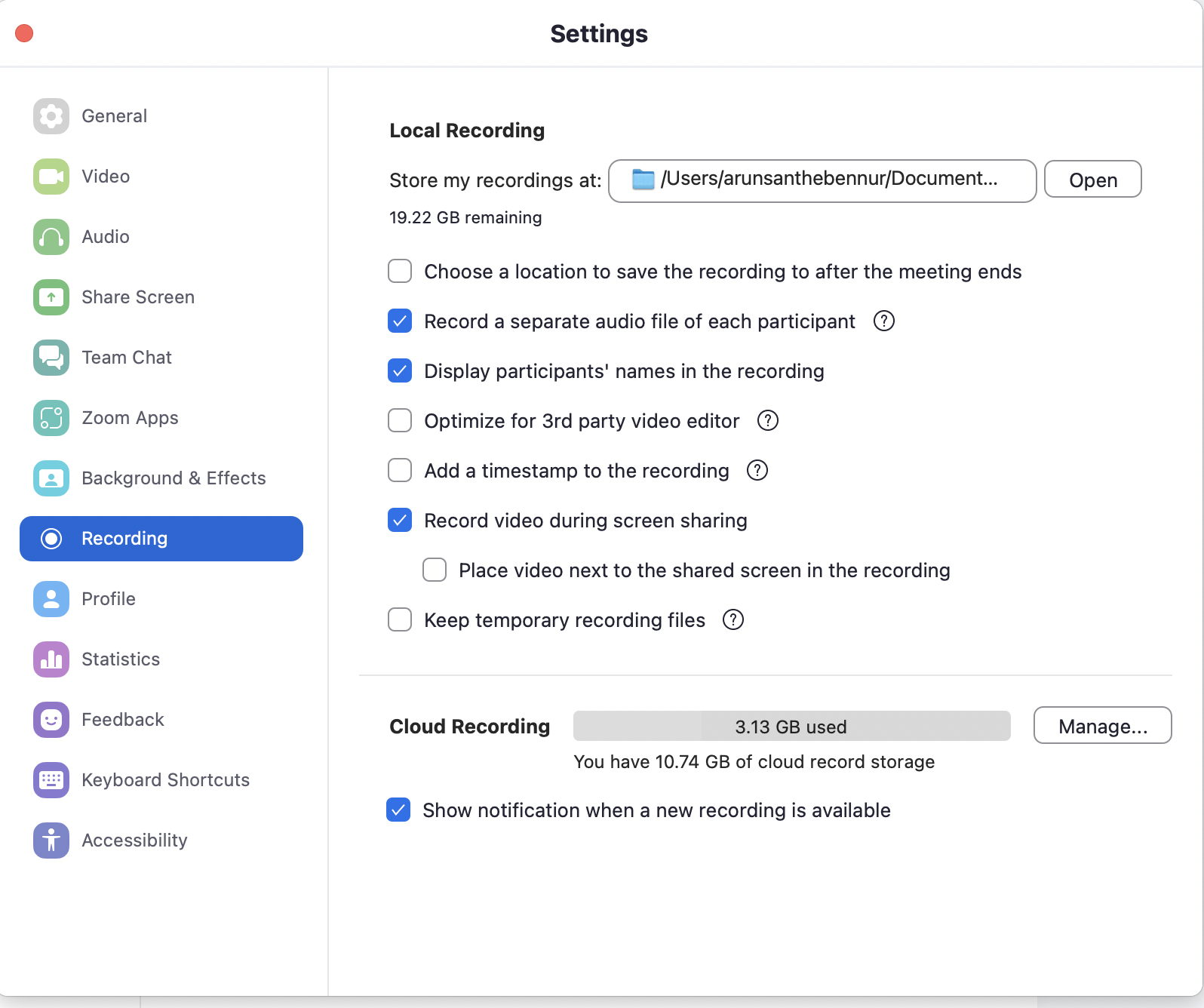
Zoom Local Recordings are recordings of your meetings that are saved in your computer's hard disk on your file-system and not on Zoom's cloud. This feature ensures that confidential and privacy-sensitive recorded audio and video content is stored within the enterprise and is not accessible to Zoom.
Voicegain offers a Windows desktop app (App for Mac OS is on the roadmap) that accesses these Zoom recordings and submits it for transcription and NLU.
The other major advantage of Zoom Local Recordings is that Zoom supports recording of a separate audio track for each participant. This feature is not available in its Cloud recording as of yet (as of Feb 2023). Voicegain Transcribe with Zoom Local Recordings can hence assign speaker labels with 100% accuracy.
There are vendors that offer Meeting Assistants that join from the Cloud and record. However when this solution is picked, the Meeting Assistant has access only to a blended/merged mono audio file which includes audio of all the participants. So Meeting AI solution has to "diarize" the meeting audio - which is an inherently difficult problem to solve. Even state-of-the-art diarization/speaker separation models are only 83-85% accurate.
For any Meeting AI solution to extract meaningful insights, the accuracy of the underlying transcription is extremely important. If the Speech-to-Text is not accurate, then even the best NLU algorithm or the largest language model cannot deliver valuable and accurate analytics.
Voicegain can train the underlying Speech-to-Text to help accurately transcribe different accents, customer specific words and the specifiic acoustic environment.
Voicegain integrates with Enterprise SSO solutions using SAML. Voicegain also integrates with internal email systems to simplify user management tasks like sign-up, password reset and changes, adds and deletes.
All the meeting audio, transcripts and NLU-based analytics are stored in enterprise controlled NoSQL and SQL databases. Enterprises can either use in-house staff to maintain/administer these databases and storage or they can also use a managed database option like MongoDB Atlas or Managed PostgreSQL from a cloud provider like Azure, AWS or GCP
If you are looking for a Meeting AI solution that can be deployed fully behind your corporate firewall or in your own Private Cloud infrastructure, then Voicegain Transcribe is the perfect fit for your needs.
Have questions? We would love to hear from you. Send us an email -sales@voicegain.ai or support@voicegain.ai and we will be happy to offer more details.
.jpg)
We are really excited to announce the launch of Zoom Meeting Assistant for Local Recordings. This is immediately available to all users of Voicegain Transcribe that have a Windows device. The Zoom Meeting Assistant can be installed on computers that have Windows 10 or Windows 11 as the OS.
What are local recordings? Zoom offers two ways to record a meeting - 1) Cloud Recording: Zoom users may save the recording of the meeting on Zoom's Cloud. 2) Local Recording - The meeting recording is saved locally on the Zoom user's computer. These recordings are saved in the default Zoom folder on the file system. Zoom processes the recording and makes it available in this folder a few minutes after the meeting is complete.
Below is a screenshot of how a Zoom user can initiate a local recording.

There are four big benefits of using Local Recordings
To use Voicegain Zoom Meeting Assistant, there are just two requirements
1. Users should first sign up for a Voicegain Transcribe account. Voicegain offers a free plan forever (up to 2 hours of transcription per month) and users can sign up using this link. You can learn more about Voicegain Transcribe here.
2. They should have a computer with Windows 10 or 11 as the OS.
This Windows App can be downloaded from the "Apps" page on Voicegain Transcribe. Once the app is installed, users will be able to access it on their Windows Taskbar (or Tray). All they need to do is to log into the Voicegain Transcribe App from the Meeting Assistant by entering their Transcribe user-id and password.
Once the Meeting Assistant App is logged into Voicegain Transcribe, it does two things
1. It constantly scans the Zoom folder for any new local recordings of Meetings. As soon as it finds such a recording, it submits/uploads it to Voicegain Transcribe for transcription, summarization and extraction of Key Items (Actions, Issues, Sales Blockers, Questions, Risks etc.)
2. It can also join any Zoom Meeting as the Users AI Assistant. Also this feature works whether the user is the Host of the Zoom Meeting or just a Participant . By joining the meeting, the Meeting Assistant is able to collect information on all the participants in the meeting.
While the current Meeting Assistant App works only for Windows users, Voicegain has native apps for Mac, Android and iPhone as part of its product roadmap.
Send us an email at support@voicegain.ai if you have any questions.

It has been another 6 months since we published our last speech recognition accuracy benchmark. Back then, the results were as follows (from most accurate to the least): Microsoft, then Amazon closely followed by Voicegain, then new Google latest_long and Google Enhanced last.
While the order has remained the same as the last benchmark, three companies - Amazon, Voicegain and Microsoft showed significant improvement.
Since the last benchmark, at Voicegain we invested in more training - mainly lectures - conducted over zoom and in a live setting. Training on this type of data resulted in a further increase in the accuracy of our model. We are actually in the middle of a further round of training with a focus on call center conversations.
As far as the other recognizers are concerned:
We have repeated the test using similar methodology as before: used 44 files from the Jason Kincaid data set and 20 files published by rev.ai and removed all files where none of the recognizers could achieve a Word Error Rate (WER) lower than 25%.
This time again only one file was that difficult. It was a bad quality phone interview (Byron Smith Interview 111416 - YouTube) with WER of 25.48%
We publish this since we want to ensure that any third party - any ASR Vendor, Developer or Analyst - to be able to reproduce these results.
You can see box-plots with the results above. The chart also reports the average and median Word Error Rate (WER)
Only 3 recognizers have improved in the last 6 months.
Detailed data from this benchmark indicates that Amazon is better than Voicegain on audio files with WER below the median and worse on audio files with accuracy above the median. Otherwise, AWS and Voicegain are very closely matched. However we have also run a client-specific benchmark where it was the other way around - Amazon as slightly better on audio files with WER above the median than Voicegain, but Voicegain was better on audio files with WER below the median. Net-net, it really depends on type of audio files, but overall, our results indicate that Voicegain is very close to AWS.
Let's look at the number of files on which each recognizer was the best one.
We now have done the same benchmark 5 times so we can draw charts showing how each of the recognizers has improved over the last 2 years and 3 months. (Note for Google the latest 2 results are from latest-long model, other Google results are from video enhanced.)
You can clearly see that Voicegain and Amazon started quite bit behind Google and Microsoft but have since caught up.
Google seems to have the longest development cycles with very little improvement since Sept. 2021 till about half a year ago. Microsoft, on the other hand, releases an improved recognizer every 6 months. Our improved releases are even more frequent than that.


As you can see, the field is very close and you get different results on different files (the average and median do not paint the whole picture). As always, we invite you to review our apps, sign-up and test our accuracy with your data.
When you have to select speech recognition/ASR software, there are other factors beyond out-of-the-box recognition accuracy. These factors are, for example:
1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click here to sign up for a developer account and receive $50 in free credits
3. If you want to take Voicegain as your own AI Transcription Assistant to meetings, click here.
.png)
Enterprises are increasingly looking to mine the treasure trove of insights from voice conversations using AI. These conversations take place daily on video meeting platforms like Zoom, Google Meet and Microsoft Teams and over telephony in the contact center (which take place on CCaaS or on-premise contact center telephony platforms).
Voice AI or Conversational AI refers to converting the audio from these conversations into text using Speech recognition/ASR technology and mining the transcribed text for analytics and insights using NLU. In addition to this, AI can be used to detect sentiment, energy and emotion in both the audio and text. The insights from NLU include extraction of key items from meetings. This include semantically matching phrases associated with things like action items. issues, sales blockers, agenda etc.
Over the last few years, the conversational AI space has seen many players launch highly successful products and scale their businesses. However most of these popular Voice AI options available in the market are multi-tenant SaaS offerings. They are deployed in a large public cloud provider like Amazon, Google or Microsoft. At first glance, this makes sense. Most enterprise software apps that automate workflows in functional areas like Sales and Marketing(CRM), HR, Finance/Accounting or Customer service are architected as multi-tenant SaaS offerings. The move to Cloud has been a secular trend for business applications and hence Voice AI has followed this path.
However at Voicegain, we firmly believe that a different approach is required for a large segment of the market. We propose an Edge architecture using a single-tenant model is the way to go for Voice AI Apps.
By Edge, we mean the following
1) The AI models for Speech Recognition/Speech-to-Text and NLU run on the customer's single tenant infrastructure – whether it is bare-metal in a datacenter or on a dedicated VPC with a cloud provider.
2) The Conversational AI app -which is usually a browser based application that uses these AI models is also completely deployed behind the firewall.
We believe that the advantages for Edge/On-Prem architecture for Conversational/Voice AI is being driven by the following four factors
Very often, conversations in meetings and call centers are sensitive from a business perspective. Enterprise customers in many verticals (Financial Services, Health Care, Defense, etc) are not comfortable storing the recordings and transcripts of these conversations on the SaaS Vendor's cloud infrastructure. Think about a highly proprietary information like product strategy, status of key deals, bugs and vulnerabilities in software or even a sensitive financial discussion prior to the releasing of earnings for a public company. Many countries also impose strict data residency requirements from a legal/compliance standpoint. This makes the Edge (On-Premises/VPC) architecture very compelling.
Unlike pure workflow-based SaaS applications, Voice AI apps include deep-learning based AI Models –Speech-to-Text and NLU. To extract the right analytics, it is critical that these AI models – especially the acoustic models in the speech-recognition/speech-to-text engine are trained on client specific audio data. This is because each customer use case has unique audio characteristics which limit the accuracy of an out-of-the-box multi-tenant model. These unique audio characteristics relate to
1. Industry jargon – acronyms, technical terms
2. Unique accents
3. Names of brands, products, and people
4. Acoustic environment and any other type of audio.
However, most AI SaaS vendors today use a single model to serve all their customers. And this results in sub-optimal speech recognition/transcription which in turn results in sub-optimal NLU.
For real-time Voice AI apps - for e.g in the Call Center - there is an architectural advantage for the AI models to be in the same LAN as the audio sources.
For many enterprises, SaaS Conversational AI apps are inexpensive to get started but they get very expensive at scale.
Voicegain offers an Edge deployment where both the core platform and a web app like Voicegain Transcribe can operate completely on our clients infrastructure. Both can be placed "behind an enterprise firewall".
Most importantly Voicegain offers a training toolkit and pipeline for customers to build and train custom acoustic models that power these Voice AI apps.
If you have any question or you would like to discuss this in more detail, please contact our support team over email (support@voicegain.ai)
.jpg)
As we announced here, Voicegain Transcribe is an AI based Meeting Assistant that you can take with you to all your work meetings. So irrespective of the meeting platform - Zoom, Microsoft Teams, Webex or Google Meet - Voicegain Transcribe has a way to support you.
We now have some exciting news for those users that regularly host Zoom meetings. Voicegain Transcribe users who are on Windows now have a free, easy and convenient way to access all their meeting transcripts and notes from their Zoom meetings. Transcribe Users can now download a new client app that we have developed - Voicegain Zoom Meeting Assistant for Local Recordings - onto their device.
With this client app, any Local Recording of a Zoom meeting (explained below) will be automatically submitted to Voicegain Transcribe. Voicegain's highly accurate AI models subsequently process the recording to generate both the transcript (Speech-to-Text) but also the minutes of the meeting and the topics discussed (NLU).
As always, you get started with a free plan that does not expire. So you can get started today without having to setup your payment information.
Zoom provides two options to record meetings on its platform - 1) Local Recording and 2) Cloud Recording.
Zoom Local recording is a recording of the meeting that is saved on the hard disk of the user's device. There are two distinct benefits of using Zoom Local Recording
Zoom Cloud Recording is when the recording of the meeting is stored on your Zoom Cloud account on Zoom's servers. Currently Voicegain does not directly integrate with Zoom Cloud Recording (however it is on our roadmap). In the interim, a user may download the Cloud Recording and upload it to Voicegain Transcribe in order to transcribe and analyze recordings saved in the cloud.
.png)
Zoom allows you to record individual speaker audio tracks separately as independent audio files. The screenshot above shows how to enable this feature on Zoom.
Voicegain Zoom Meeting Assistant for Local Recording supports uploading these independent audio files to Voicegain Transcribe so that you can get accurate speaker transcripts
The entire Voicegain platform including the Voicegain Transcribe App and the AI models can be deployed On-Premise (or in VPC) giving an enterprise a fully secure meeting transcription and analytics offering.
If you have any question, please sign up today, and contact our support team using the App.

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices