On this page
[UPDATE - October 31st, 2021: Current benchmark results from end October 2021 are available here. In the most recent benchmark Voicegain performs better than Google Enhanced.]
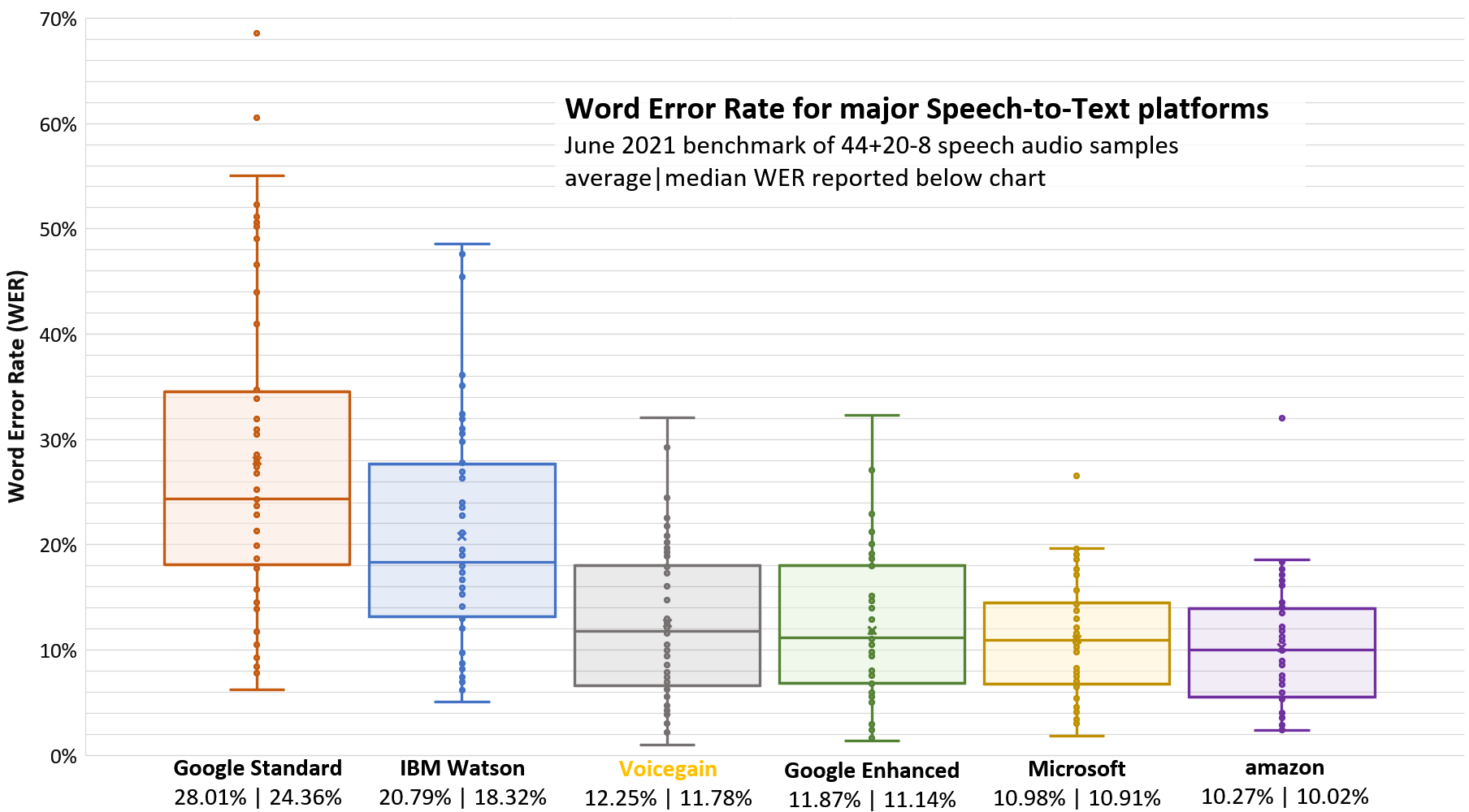
It has been over 8 months since we published our last speech recognition accuracy benchmark (described here). Back then the results were as follows (from most accurate to least): Microsoft and Google Enhanced (close 2nd), then Voicegain and Amazon (also close 4th) and then, far behind, Google Standard.
Methodology
We have repeated the test using the same methodology as before: take 44 files from the Jason Kincaid data set and 20 files published by rev.ai and remove all files where the best recognizer could not achieve a Word Error Rate (WER) lower than 20%. Last time we removed 10 files, but this time as the recognizers improved only 8 files had their WER higher than 20%.
The files removed fall into 3 categories:
- recordings of meetings - 3 files (3 out of 7 meeting recordings in the original set),
- telephone conversations - 3 files (3 out of 11 phone phone conversations in the original set),
- multi-presenter, very animated podcasts - 2 files (there were a lot of other podcasts in the set that did meet the cut off).
Some of our customers told us that they previously used IBM Watson, so we decided to add also it to the test.
Results
In the new test, as you can see in the results chart above, the order has changed: Amazon has leap-frogged everyone by increasing its median accuracy by over 3% to just 10.02%, it is now in the pole position. Microsoft, Google Enhanced and Google Standard performed at approximately the same level. The Voicegain recognizer improved by about 2%. The newly tested IBM Watson is better than Google Standard, but lags the other recognizers.
Voicegain is tied with Google Enhanced
New results put Voicegain recognizer very close to Google enhanced:
- Average WER of Voicegain is just 0.66% behind Google, while median WER is just 0.63% behind. To put it in context - Voicegain makes one additional mistake every 155 words compared to Google Enhanced.
- Voicegain was actually marginally better than Google Enhanced on the min error, 1st quartile, 3rd quartile, and max error.
- Overall Voicegain was better on 20 files while Google was better on 36 files.
However the results for a use case depends on the specific audio - for some of them Voicegain will perform slightly better and for some Google may perform marginally better. As always, we invite you to review our apps, sign-up and test our accuracy with your data.
What about Open Source recognizers
We have looked at both the Mozilla DeepSpeech and Kaldi projects. We ran our complete benchmark on Mozilla DeepSpeech and found that it significantly trails behind Google Standard recognizer. Out of 64 audio files, Mozilla was better than Google Standard on only 5 files and tied on 1. It was worse on the remaining 58 files. Median WER was 15.63% worse for Mozilla compared to Google Standard. The lowest WER of 9.66% for Mozilla DeepSpeech was on audio from Librivox "The Art of War by Sun Tzu". For comparison, Voicegain achieves 3.45% WER on that file.
Regarding Kaldi we have not benchmarked it yet, but from the research published online it looks like Kaldi trails Google Standard too, at least when used with its standard ASpIRE and LibriSpeech models.
Out-of-the-box accuracy is not everything
When you have to select speech recognition/ASR software, there are other factors beyond out-of-the-box recognition accuracy. These factors are, for example:
- Ability to customize the Acoustic Model - Voicegain model may be trained on your audio data - we have demonstrated improvement in accuracy of 7-10%. In fact for one of our customers with adequate training data and good quality audio we were able achieve a WER of 0.5% (99.5% accuracy)
- Ease of integration - Many Speech-to-Text providers offer limited APIs especially for developers building applications that require interfacing with telephony or on-premise contact center platforms.
- Price - Voicegain is 60%-75% less expensive compared to other Speech-to-Text/ASR software providers while offering almost comparable accuracy. This makes it affordable to transcribe and analyze speech in large volumes.
- Support for On-Premise/Edge Deployment - The cloud Speech-to-Text service providers offer limited support to deploy their speech-to-text software in client data-centers or on the private clouds of other providers. On the other hand, Voicegain can be installed on any Kubernetes cluster - whether managed by a large cloud provider or by the client.
Take Voicegain for a test drive!
1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click hereto sign up for a developer account and receive $50 in free credits
3. If you want to take Voicegain as your own AI Transcription Assistant to meetings, click here.
Published by



