On this page
IntroductionWhy a call center benchmarkMethodologyThe resultsCustom trainingOn-premises advantageStreaming performanceReproducing the benchmarkSome of the feedback that we received regarding the previously published benchmark data, see here and here, was concerning the fact that the Jason Kincaid data set contained some audio that produced terrible WER across all recognizers and in practice no one would user automated speech recognition on such files. That is true. In our opinion, there are very few use cases where WER worse than 20%, i.e. where on average 1 in every 5 words is recognized incorrectly, is acceptable.
New Methodology
What we have done for this blog post is we have removed from the reported set those benchmark files for which none on the recognizers tested could deliver WER 20% or less. This criterion resulted in removal of 10 files - 9 from the Jason Kincaid set of 44 and 1 file from the rev.ai set of 20. The files removed fall into 3 categories:
- recordings of meetings - 4 files (this amounts to half of the meeting recordings in the original set),
- telephone conversations - 4 files (4 out of 11 phone phone conversations in the original set),
- multi-presenter, very animated podcasts - 2 files (there were a lot of other podcasts in the set that did meet the cut off).
The results
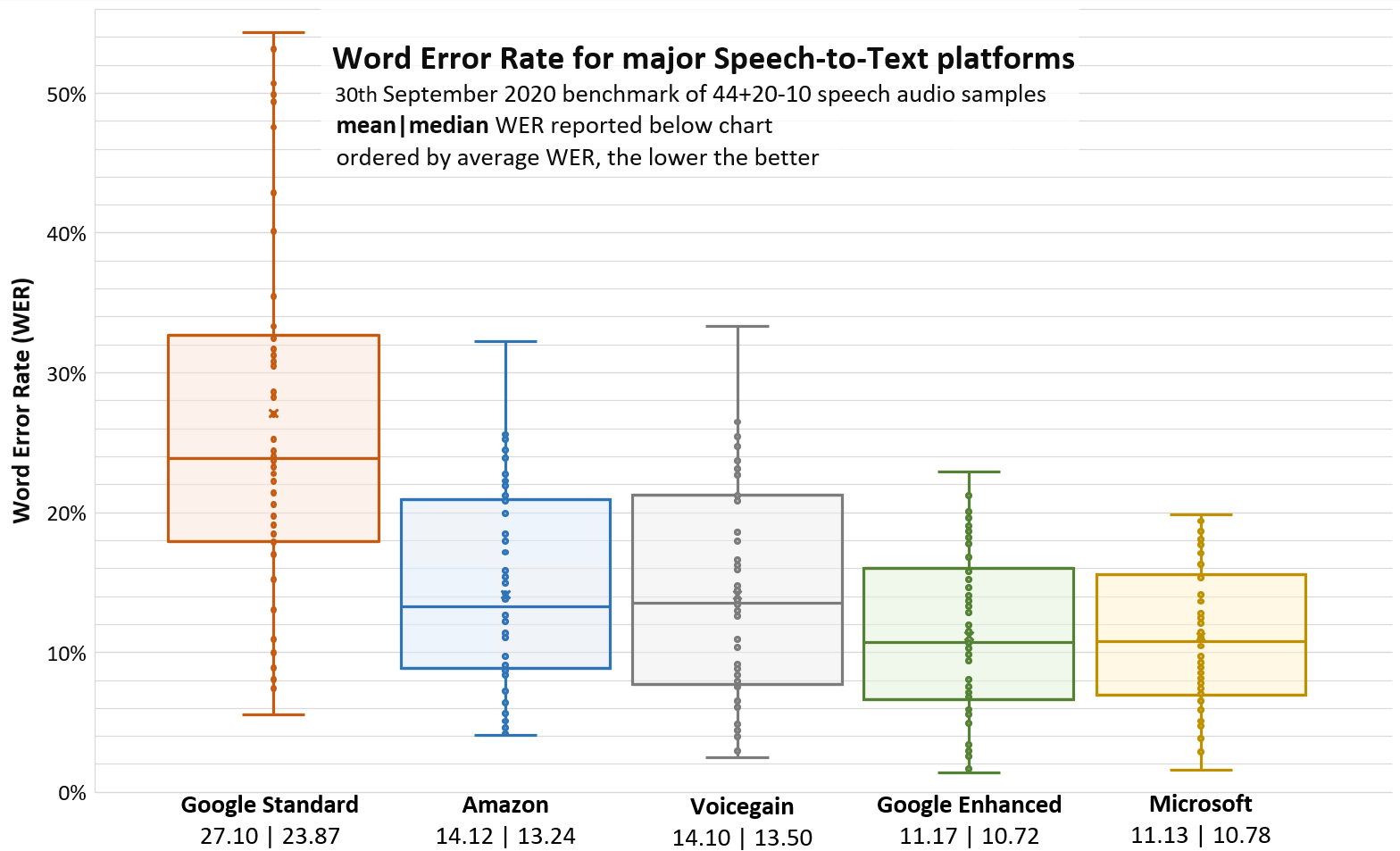
As you can see, Voicegain and Amazon recognizers are very evenly matched with average WER differing only by 0.02%, the same holds for Google Enhanced and Microsoft recognizer with the WER difference being only 0.04%. The WER of Google Standard is about twice of the other recognizers.
Published by