

Products
AI Voice Agent Platform
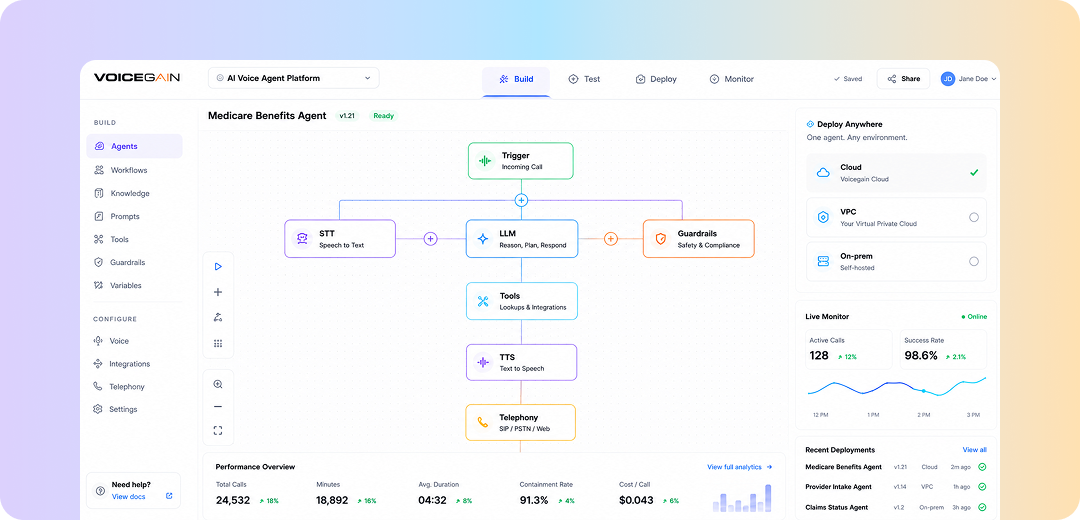
Build LLM-powered AI Voice Agents
Explore more →
MRCP ASR
ASR for VoiceXML IVR Platforms
Explore more →

Developers
APIs, SDKs, Docs & Pricing
Explore more →

By Industry
Healthcare Payers
Help
Documentation
↗Implementation guides
Status Page
↗System health & uptime
Support
↗Get help from the team
Voice AI for CX
Under Your Control
Casey, a pre-built Voice AI Suite for healthcare payers. Or the Voicegain Platform to build your own Voice AI. Deploy in our cloud, your VPC, or fully on-prem.

Trusted by HEALTH PLANS, TPAS, AND PRODUCT TEAMS building amazing voice AI products














