Speech-to-Text (STT) APIs enable developers to embed AI-based transcription into any voice-enabled app. STT APIs provide access to Voicegain's highly accurate & trainable batch and streaming deep-learning-based STT models.


Invoke our STT APIs using our highly scalable cloud service or deploy a containerized version of Voicegain in your VPC or datacenter. Our AI models convert audio/video files in batch or a real-time media stream into text and we support 40+ audio formats.
On a broad benchmark, our accuracy of 89% is on par with the very best
Talk to us in English, Spanish, German, Portuguese, Korean (more coming)
Tested on compute instances on Google, AWS, Azure, IBM & Oracle
Integrates with Twilio, Genesys, FreeSWITCH and other CCaaS and CPaaS platforms

Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
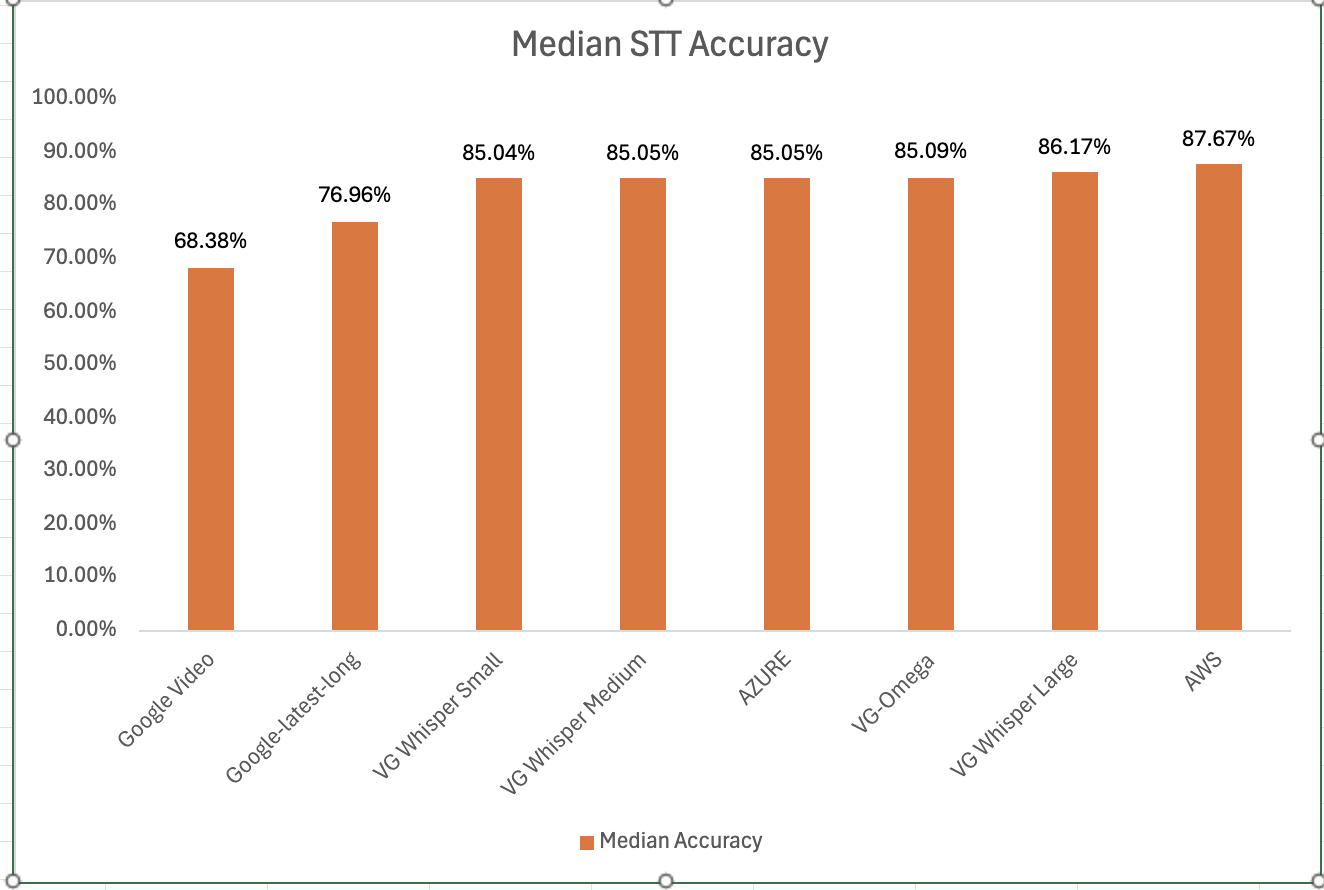
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

This article is for companies building Voice AI Apps targeting the Contact Center. It outlines the key technical features, beyond accuracy, that are important while evaluating an OEM Speech-to-Text (STT) API. Usually, most analyses focus on the importance of accuracy and metrics like benchmarks of word error rates (WER). While accuracy is very important, there are other technical features that are equally important for contact center AI apps.
There are multiple use-cases for Voice AI Apps in the ContactCenter. Some of the common use cases are 1) AI Voicebot or Voice Agent 2) Real-time Agent Assist 3)Post Call Speech Analytics.
This article is focused on the third use-case which is Post-Call Speech Analytics. This use-case relies on batch STT APIs while the first two use-cases require streaming transcription. This Speech Analytics App helps the Quality Assurance and Agent-Performance management process. This article is intended for Product Managers and Engineering leads involved in building such AI Voice Apps that target the QA, Coaching and Agent Performance management process in the call center. Companies building such apps could include 1) CCaaS Vendors adding AI features, 2) Enterprise IT or Call Center BPO Digital organizations building an in-house Speech Analytics App 3) Call Center Voice AI Startups
Very often, call-center audio recordings are only available in mono. And even if the audio recording is in 2-channel/stereo, it could include multiple voices in a single channel. For example, the Agent channel can include IVR prompts and hold music recordings in addition to the Agent voice. Hence a very important criterion for an OEM Speech-to-Text vendor is that they provide accurate speaker diarization.
We would recommend doing a test of various speech-to-text vendors with a good sample set of mono audio files. Select files that are going to be used in production and calculate the Diarization Error Rate. Here is a useful link that outlines the technical aspects of understanding and measuring speaker diarization.
A very common requirement of Voice AI Apps is to redact PII – which stands for Personally Identifiable Information. PII Redaction is a post-processing step that a Speech-to-Text API vendor needs to perform. It involves accurate identification of entities like name, email address, phone number and mailing addresses and subsequent redaction both in text and audio. In addition, there are PCI – Payment Card Industry – specific named entities like Credit Card number, 3-digit PIN and expiry dates. Successful PII and PCI redaction requires post-processing algorithms to accurately identify a wide range of PII entities and cover a wide range of test scenarios. These test scenarios need to cover scenarios where there errors in user input and errors in speech recognition too.
There is another important capability related to PCI/PII redaction. Very often PII/PCI entities are present across multiple turns in a conversation between an Agent and Caller. It is important that the post-processing algorithm of the OEM Speech-to-Text vendor is able to process both channels simultaneously when looking for these named entities.
A Call Center audio recording could start off in one languageand then switch to another. The Speech-to-Text API should be able to detect language and then perform the transcription.
There will always be words that are not accurately transcribed by even the most accurate Speech-to-Text model. The API should include support for Hints or Keyword Boosting where words that are consistently misrecognized can get replaced by the correctly transcribed word. This is especially applicable for names of companies, products and industry specific terminology.
There are AI models that measure sentiment and emotion, and these models can be incorporated in the post-processing stage of transcription to enhance the Speech-to-Text API. Sentiment is extracted from the text of the transcript while Emotion is computed from the tone of the audio. A well-designed API should return Sentiment and Emotion throughout the interaction between the Agent and Caller. It should effectively compute the overall sentiment of the call by weighting the “ending sentiment” appropriately.
While measuring the quality of an Agent-Caller conversation, there are a few important audio-related metrics that are tracked in a call center. These include Talk-Listen Ratios, overtalk incidents and excessive silence and hold.
There are other LLM-powered features like computation of theQA Score and the summary of the conversation. However, these are features are builtby the developer of the AI Voice App by integrating the output of the Speech-to-TextAPI with the APIs offered by the LLM of the developer’s choice.
“We selected Voicegain because they are accurate, affordable and easy to use. We deployed the entire platform in our datacenter in under 30 minutes.”
“We selected Voicegain for Sutherland CX360, our AI/ML SaaS offering to evaluate all of Sutherland’s CX interactions. We were looking for an accurate PCI-compliant ASR/STT offering for our enterprise customers and we found that in Voicegain..”
“Voicegain is amazing! They have a great ASR and a modern architecture. But what we really value is their prompt and timely support. We use both their MRCP ASR and STT APIs and they work great “
Interested in customizing the ASR or deploying Voicegain on your infrastructure?
Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices