On this page
[UPDATE - October 31st, 2021: Current benchmark results from end October 2021 are available here. In the most recent benchmark Voicegain performs better than Google Enhanced.]
"What is the accuracy of your recognizer?"
That is the question that we are frequently asked by our potential customers. Often we answer "that depends" and we get a feeling that the other side thinks "must be really bad if they do not give a straight answer". However, "that depends" is really the right answer. Accuracy of automated speech recognition (ASR) depends on the audio in many ways and the effect is not small. Basically, accuracy can be all over the place depending on factors like:
- Does the speech follow proper grammar or is the speaker making things up as they are saying it. Prepared speeches will have better, i.e. lower WER (word error rate) scores compared to unscripted speech.
- What is the subject of the speech. Rare and obscure words or word combinations, like e.g. people or other names, will make life difficult for the NLM (natural language model).
- Are there more than one speakers? Are they constantly switching over or even talk over one another.
- Is there music in the background - very common for youtube productions.
- Is there background noise? What is the type of noise?
- Are parts of the speech audio unusually slow or fast?
- Is there room reverb or echo in the recording?
- Is the recording volume very low. Are there variations in the recording volume (e.g. recorder placed on one edge of a very long table)
- Is the recording quality bad, e.g., due to a codec or insane archival compression levels.
- etc. etc.
Testing / Benchmarking Speech-to-Text Accuracy
Because the accuracy or Word Error Rate questions are somewhat meaningless without specifying the type of speech audio, it is important to do testing when choosing a speech recognizer. As a test set, one would choose a set of audio files, that accurately represent the spectrum of the speech that will be encountered by the recognizer in the expected use cases. For each speech audio file from the set one would obtain a gold/reference transcript that is 100% accurate. After that, things can be automated -- transcribe each file on the recognizers being evaluated, compute WER against the reference for each of the generated transcripts, and collate the results. The combined results will present a clear picture of how the recognizers perform on the specific speech audio that we care about. If you are going to repeat this process often, e.g., to evaluate new candidates on the recognizer marker, it is good to standardize the test set, basically creating a repeatable benchmark that can be referenced in the future.
Our benchmark
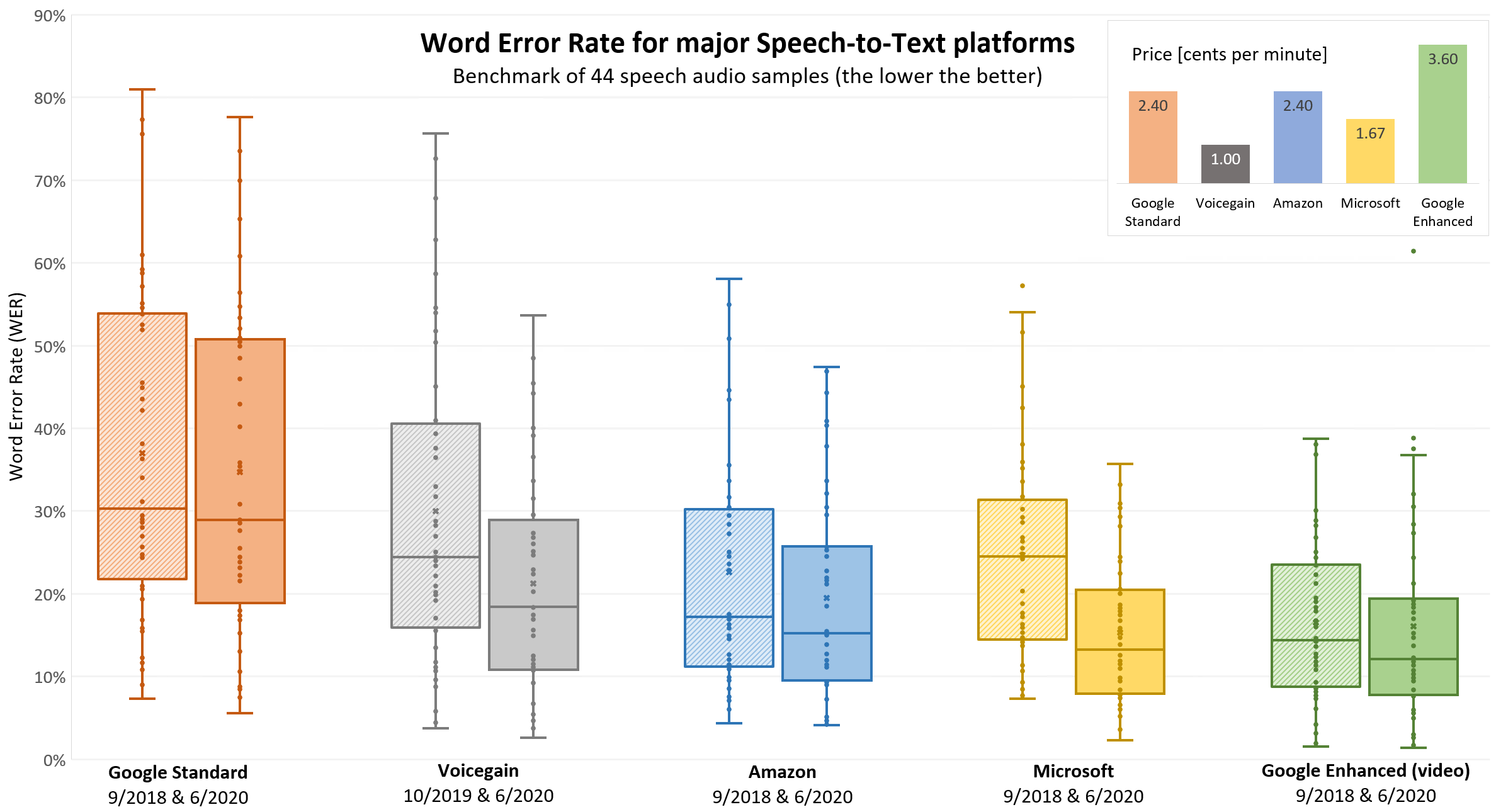
The benchmark results that we are presenting here are somewhat different than the use-case driven tests or benchmarks. Because we are building a general recognizer for an unspecified use case, we intentionally decided to use a very broad set of audio files. Rather than collecting the test files ourselves, we decided to use the data set described in "Which Automatic Transcription Service is the Most Accurate? — 2018" from September 2018 by Jason Kincaid. The article presents a comparison of Speech Recognizers from various companies using a set of 48 YouTube videos (taking 5 minutes of audio from each of the videos). By the time we decided to do a retest of Jason's benchmark, 4 videos were no longer accessible, so our benchmark presented here uses data from only 44 videos.
We compared the results presented by Jason to the results from the big 3 - Google, Amazon, and Microsoft - recognizers as of June 2020. Of course, we also included our Voicegain recognizer, because we wanted to see how we stacked against those. All the tested recognizers use Deep Neural Networks. The Voicegain speech recognizer ran on the Google Cloud Platform using Nvidia T4 GPUs. All recognizers were run with default settings and no hints nor user language models were used.
It is important to mention that none of the benchmark files are included in the training set that Voicegain uses. Neither is other audio from the speakers from the benchmark files, nor the same content but spoken by other speakers.
So what are the results? Who has the best recognizer?
Again, the best recognizer is not the right question, because it all depends on your actual speech audio it is used on. But the key results from testing on the 44 files are as follows:
- Every recognizer has improved. The biggest improvement in median WER was by Microsoft Speech to Text.
- The best recognizer in our data set was Google Speech to Text - Enhanced (video), but the new Microsoft Speech to Text is very close second.
- Taking price into consideration, Microsoft might be declared Best Buy
- Voicegain recognizer is definitely Best Value.
- Google Speech to Text - Standard, although somewhat improved, is still clearly the worst performing on the data set.
- The single bad data point for Google Enhanced (video) is real. We ran repeated test on the file and got the same result. The old Google Enhanced recognizer did not have problems with that file.
How does the Voicegain recognizer stack up?
Here are our thoughts and some details:
- Up until October 2019 the training set we were using to train our recognizer was relatively unchanged. Moreover, our training set was heavily biased towards some categories of speech audio. You can see that in the chart, e.g., by the fact that our best results were better than old Amazon Transcribe but our worst results were quite a bit more worse than Amazon Transcribe.
- Based on the first results from the benchmark we analyzed what kind of audio gave us trouble, and collected data with the particular characteristics but sourced very broadly (to avoid training to benchmark) to make our recognizer more robust. That effort paid off and you can see that now the Voicegain recognizer WER spread is much tighter and overall is now very close to new Amazon Transcribe.
- Overall Voicegain is the most improved recognizer. Just over 6 months ago we were just better than Google Standard, but now we are closing on Amazon Transcribe. This is result of both changes to the Neural Network architecture and a large increase in the training data set hours.
- If you look into the details, Voicegain recognizer was better than new Amazon on 11 out of 44 files, better than Google Video on 5 files, and better than Microsoft also on 5 out of 44 files.
- If you consider the price, we think that Voicegain presents a great value. We have talked to customers who were not doing large scale transcription due to large cost of the 3 big platforms and our low pricing suddenly made new uses of transcription viable.
We welcome anyone to test our platform and see how it performs on speech audio types that matter for your use cases.
Any software that can help me in testing recognizers?
We have Open Sourced the key component of our benchmark suite, the transcribe_compare python utility. It is available here: https://github.com/voicegain/transcription-compare under MIT license.
It is useful for automatic benchmarking but it can also output data to an html file which can be viewed in a web browser. We use it often this way to do a manual review of the transcription errors or differences in errors between two recognizers or recognizer versions.
How can I test drive Voicegain?
If you are building an app that requires transcription, sign up today for a developer account and get $50 in free credits (~5000 minutes of platform use). You can check out our accuracy add test our APIs. Instructions to sign up for a developer account are provided here.
3. If you want to make Voicegain your own AI Transcription Assistant, click here. You can take Voicegain to meetings, webinars, talks, lectures and more.
We expect to catch up soon
We are still in the middle of extensive data collection effort and the training is not over yet. We are seeing continuing improvement in our recognizer, with the new improved versions of the acoustic model deployed to production about twice a month. We will report updated benchmark results on our blog in a few months.
User-Customized Acoustic Model
We have another blog post planned that is going to quantify the benefit one can expect from using additional user data to train the acoustic model used in the recognizer. We have selected a large data set with a very specific English accent that currently has higher WER. We will report on the impact on WER of training on such a data set. We will quantify the improvement based on the size of the data set and the duration of training.
Voicegain provides easy to use tools that allow users to build their own custom acoustic models. This upcoming post will provide a clear insight as to what improvements to expect and how much data is needed to make a difference in reducing WER.
References
- The original benchmark article with the description of the data set.
- Detailed results for all 44 files.
- Google Speech-to-Text pricing. Billed in 15-second increments.
- Amazon Transcribe pricing. Billed in one-second increments, with a minimum per request charge of 15 seconds
- Microsoft Speech-to-Text pricing. And here are the relevant FAQs.
- Voicegain Pricing. Billed in 1 second increments.
Contact Us
If you have any questions regarding this article or our platform and recognizer you can contact us at info@voicegain.ai
Published by



