
Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
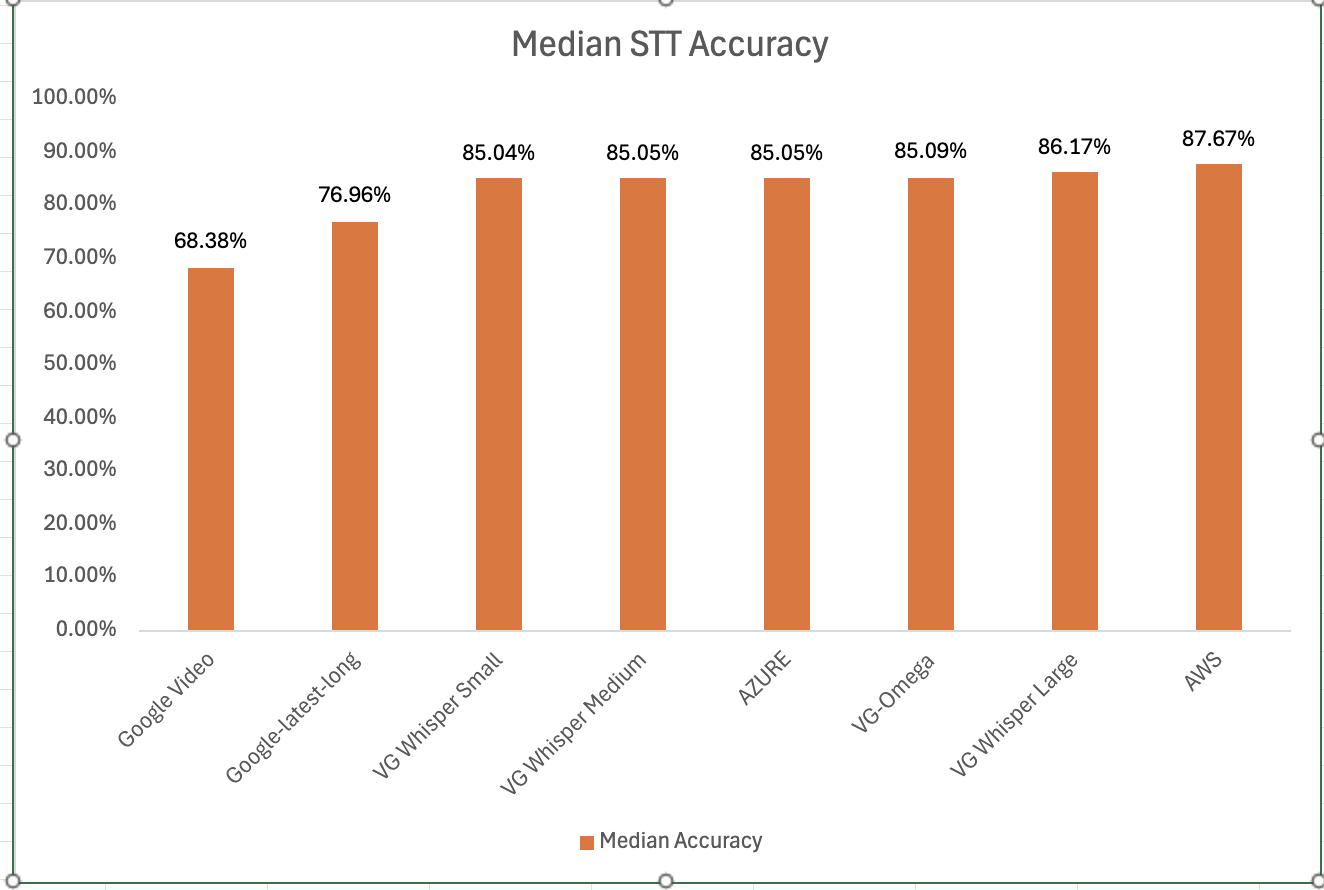
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

Digital Transformation efforts in most enterprises have only gained pace as a result of the pandemic. The maxim going around in corporate circles in 2020 (and very likely to continue in 2021) is that the coronavirus was the real Chief Digital Officer (CDO) for most enterprises!! CIOs, CTOs and the CDOs today have stronger and bolder mandates to fundamentally alter the economics of their businesses.
They are increasingly being asked by their CEOs to make big bets and take on initiatives that can "materially" transform the underlying economics of their businesses.
A significant area of focus for digital enterprises is what is being referred to as "Practical AI". How businesses use AI and ML in a practical yet fundamental manner to transform themselves? Enterprises in different industries - financial services, travel, telecommunications, media and retail - are realizing that investing in strong AI & ML capabilities in their teams is critical to their post-pandemic digital future. In many Fortune 1000 companies, businesses are 'insourcing' and aggressively hiring AI & ML teams even as they outsource maintenance of legacy back-end systems to gain competitive advantage.
And one of the most practical AI applications in the enterprise is Voice AI - which refers to the use of AI & ML on voice conversations within the enterprise.
Despite the proliferation of digital channels like chat/text messaging, email and social, higher value sales conversations, meetings, and involved customer service discussions are conducted pre-dominantly over voice. Speaking is not just more efficient than typing, it is also more engaging!! The human touch with voice is something that we as humans will always value. Voice is here to stay and its enduring significance is as immutable as the laws of gravity!
So what is changing in the world of Voice? It is just that the underlying plumbing is transforming - voice conversations traditionally took place over legacy telephony networks. They are quickly moving to meeting platforms like Zoom, Microsoft Teams and Webex; so a voice only conversation is being replaced by a richer voice & video conversation conducted over the internet.
The barriers historically associated with voice - costs and complexity of voice infrastructure- have been eliminated with technologies like WebRTC, 4G/5G and cloud computing. For consumers, the cost of making a voice call is now zero - it is the cost of their WiFi or 4G/5G bandwidth (as consumers use free mobile apps like Facetime, Skype and WhatsApp).
Voice AI is highly accurate Speech-to-Text and NLU that is built on highly specialized and customizable (trainable) Deep Neural Networks running on GPUs.
What is unique about Deep Neural Networks is that the underlying Speech-to-Text and NLU models can be trained - easily and affordably - on enterprise specific datasets. You can leverage enterprise's lexicon and corpus - both voice & text. So instead of a 'one-size-fits-all approach', each enterprise can have its own Voice AI infrastructure - that is trained on its product names, industry jargon, employee & customer names, unique accents etc. Once it is trained, there are two big applications - 1) Voice AI for Automation and using 2) Voice AI for Analytics.

Enterprises can build Voice bots to intelligently respond to contact requests from their prospects and customers anytime anywhere. Voice Bots may also be used to respond to internal employees queries in a service/help desk context. The automation use-case is one that has really accelerated during the pandemic. Bots can help businesses deal with massive disruption caused by everyone - in sales, customer success and service - working from home during the pandemic. McKinsey has written about automation using AI.

Voice AI also makes it possible for businesses to transcribe 100% of their voice conversations and subsequently mine the text for sentiment and analytics/insights.
With Voice AI, businesses can ensure that its frontline sales staff is able to pitch its core value proposition, benefits, product and service features in a consistent and compelling manner. This can be a massive boost to sales teams as they can improve conversion ratios and accurately forecast pipeline with Voice AI.
Voice AI can also ensure that customer success and service personnel are provided with tailored/customized insights to improve not just their efficiency (metrics like AHT in contact center) and but also enhance effectiveness measures like CSAT and NPS scores.
At Voicegain, we are passionate about helping enterprises, small and mid-size businesses, entrepreneurs and startup companies with their Voice AI efforts. Our mission is to build the world's most open developer friendly Voice AI platform. Be a part of our mission by signing up here. You can transcribe your calls/meetings, try out our APIs, building amazing telephony bots and more !
About the Author:
Arun Santhebennur is the Co-founder & CEO of Voicegain. To have a more in-depth conversation, please connect with Arun on LinkedIn or send us an email.

Developers building voice-enabled SaaS applications that embed Speech-to-Text or Transcription as part of their product have multiple vendors to choose from.
However, the decision to pick the right Speech-to-Text platform or API is rather involved. This writeup outlines three types of vendors and the three key criteria (summarized as the 3 As - Accuracy, Affordability and Accessibility) to consider while making that choice.
Most voice-enabled SaaS apps that incorporate Speech-to-Text APIs broadly fall into two categories 1) Analytics and 2) Automation.
Whether you are developing an analytics app or an automation app, developers have the following vendor choices.
There are 3 distinct types of vendors

The first set of choices for most developers are Speech-to-Text APIs from the big cloud companies - Google, Amazon and Microsoft. These big players offer Speech-to-Text APIs as part of their portfolio of Cloud AI & ML services. The strategy for the Big Cloud providers is to sell their entire stack - from cloud infrastructure to APIs and even products.
However the Cloud service providers may compete directly with the developers they look to serve. E.g. Amazon Connect directly competes with Contact Center platforms that are hosted on AWS. Google Dialogflow directly competes with other NLU startups that may be looking to build and offer Voice bots and Voice Assistants to enterprises.
Other than the big 3, Nuance and IBM Watson are large companies that have a rich history of providing Automated Speech Recognition (ASR). Of the two, Nuance is better known and has been a dominant player both in the enterprise call center market with its Nuance ASR engine and in the medical transcription space with its Dragon offering. IBM has a long history of fundamental speech recognition and IBM Watson Speech-to-Text is their developer oriented offering.
Voicegain.ai, our company, plays alongside other startup companies like Deepgram that target SaaS developers with their best-of-breed DNN based speech-to-text. Since these startups are specialized providers, they are focused on beating the big cloud providers and legacy players with respect to price, performance and ease of use.
The key criteria while picking an ASR or Speech-to-Text platform are the 3 As - Accuracy, Affordability and Accessibility.
The first and most important criteria for any Speech-to-Text platform is recognition accuracy. However accuracy is a tricky metric to assess and measure. There is no 'one-size-fits-all' approach to accuracy. We have shared our thoughts & benchmarks here. While Voicegain matches or exceeds the "out-of-the-box" transcription accuracy of most of the larger players, we suggest that you do additional diligence before making a choice. The audio datasets used in these benchmarks may or may not be similar to the use case or context for which the developer intends to use the API.
While accuracy is usually measured using Word Error Rate (WER), it is important to note that this metric too has limitations. For a SaaS app, getting some important and critical words right may be even more important than just a low overall WER.
That being said, it is important for developers to establish and calculate a quick baseline "out-of-the-box" accuracy for their application with their audio datasets.
At Voicegain, we have open sourced tools to benchmark our performance against the very best in business. We strongly recommend that developers & ML Engineers calculate a benchmark baseline accuracy for their vendor choices using a statistically significant volume of audio datasets for their application.
From a developer perspective, a baseline accuracy measure will provide insights into the how closely your datasets match the datasets that the underlying STT models from the vendors have been trained on.
Here are a set of important factors that may affect your "out-of-the-box" accuracy:
Developers also need to establish a "Target" accuracy that their SaaS application or product requires. Usually Product Managers determine this based on their needs.
It is possible to bridge the gap between the Target Accuracy and the Baseline "out-of-the-box" accuracy. While it is outside the scope of this post, here is an overview of some ways in which developers can improve upon the Baseline accuracy.
However not all Speech-to-Text platforms support one or more of these options.
At Voicegain.ai, we support all the above options. Picking the right approach involves a more in-depth technical conversation. We invite you to get in touch with us.
To summarize, the choice may not be as simple as picking the one with the best "out-of-the-box' accuracy. It could in fact be a platform that provides the most convenient and least expensive path to bridge the gap between Target and Baseline accuracy.
The second most important factor after accuracy is price. Most SaaS products are very disruptively priced. It is not uncommon for the SaaS product to be sold at 'tens of dollars' ($35-100) per user per month. It is critical that Speech-to-Text APIs make up as small a fraction of the SaaS price as possible. The price directly impacts the "gross-margin" of the SaaS application, a critical financial metric/KPI that SaaS companies care dearly about.
In addition to the top-line usage based price for the platform, it is also important to understand what the minimum billable time and billing increment for each interaction. Many of the large Cloud providers have a very high minimum billable times - 12 or 18 seconds. This makes it very expensive for Voice Bots or Voice Assistant.
Another cost related aspect is the price for transcribing multi-channel audio, where only one speaker is active at the time. Does the platform charge for transcribing silence on the inactive channel ?
The last (but not the least!) important criterion is how accessible - or in other words how simple and easy is it to integrate the Speech-to-Text platform with the SaaS Application.
This ease of integration becomes even more important if the SaaS Application streams audio real-time to the Speech-to-Text platform. Another important criterion for real-time streaming is latency - which is the time to receive recognition results from the platform. For a Bot or Voice Assistant, it is important to get API latency down to 500 milliseconds or lower. Also, reliable and fast end-of-speech detection is crucial in those scenarios for natural dialog turn taking.

At Voicegain, we support multiple options - ranging from TCP-based methods like gRPC and Websockets to telephony/UDP protocols like SIP/RTP, MRCP and SIPREC.
The choice made by the developer depends on the following factors:
In conclusion, selecting the right Speech-to-Text or ASR platform for a SaaS application is a diligent exercise; it is by no means a slam dunk!!
1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click hereto sign up for a developer account and receive $50 in free credits
3. If you want to take Voicegain as your own AI Transcription Assistant to meetings, click here.

Voicegain Speech-to-Text and Speech Analytics platform supports SIPREC protocol as one of the ways an audio stream of a telephone call can be fed to the speech recognizer.
The Session Recording Protocol (SIPREC) is an open SIP-based protocol for call recording. The standard is defined by Internet Engineering Task Force. It is supported by many phone platforms and call recording system vendors.
The SIPREC standard defines a protocol used to interact between a Session Recording Client (the role generally performed by PBX system or Session Border Controller) and a Session Recording Server (a third party call recorder, in our case a Voicegain-provided SIPREC server). SIPREC opens two RTP streams (one for inbound and one for outbound audio of the call) to the Recording Server. SIPREC protocol also is able to transfer call metadata to the Recorder, this is important so that the recordings can be tied to the information about the calls.
SIPREC is usually used for call recording but the standard essentially provides a real-time audio stream from the telephone call which makes it suitable for applications which have to work real-time like, e.g., agent assist or agent monitoring. Using the SIPREC interface Voicegain can provide real-time transcript of the call as well as perform speech analytics tasks in real time, e.g., keyword and phrase detection, personally-identifiable information scrubbing, sentiment and mood estimation, named-entity recognition, and variety of metrics (like silence, overtalk, etc.).
Audio obtained via SIPREC can also be recorded and transcribed, analyzed, or retrieved at a later time.
Voicegain SIPREC interface has been tested with the following platforms:
Voicegain can capture relevant call metadata in addition to obtaining the audio (the metadata capture functionality may differ in capabilities depending on the client platform).
Voicegain platform can be configured to automatically launch transcription and speech-analytics as soon as the new SIPREC session gets established.
The output from transcription and speech analytics is available via a Web API. We also support websockets for more convenient streaming of the transcription and/or speech analytics data. SIPREC support is available both in the Cloud and the Edge (OnPrem) deployments of the Voicegain Platform.
SIPREC is an Enterprise feature of the Voicegain platform and is not included in the base package. Please contact support@voicegain.ai or submit a Zendesk ticket for more information about SIPREC and if you would like to use it with your existing Voicegain account.
Genesys Voice Platform does not support SIPREC directly. However, it does support streaming of the inbound and outbound RTP media to two separate SIP endpoints - the end result being pretty much the same as if SIPREC was used. We are currently working on implementing support for this feature of the Genesys Voice Platform for real-time audio streaming to Voicegain Platform. It should be available in Q1 2021.

In latest Voicegain release (1.16.0) we have added a new option to our /asr/recognize/async API for ASR/speech-to-text. It is called continuousRecognition and if enabled modifies the default behavior of the grammar-based recognition.
Normally when /asr/recognize/async API is used the recognizer will return when the grammar is matched and the complete timeout expires. That means that it is only possible to get a single recognition in one /asr/recognize/async API request. If a no-match or no-input is detected the recognition will terminate.
However, sometimes there are use cases which demand that the recognizer e.g. ignores all no-matches until a match is found. This is what the continuousRecognition option is for.
With continuousRecognition you have fine control over which of the 4 events - no-input, no-match, match, and error - will be returned in a callback and which (if any) event will terminate recognition. If you do not set any event to terminate recogntion, the recognition session can be stopped by closing the audio stream or by returning stop:true from the callback.
An example might be a use case where a voicemail is being played to a caller and during the playback we want to interpret caller commands like: stop, next, previous, save, delete. If we used normal recognition we would encounter situations where what is said was not understood. Stopping recognition on no-match would not make much sense because either: (1) re-prompting would mess up the flow of the call, or (2) restarting recognition might introduce a gap in recognition that may result in missing a part what the caller said.
In scenario like this it is best to ignore no-match and continue to listen, the caller will notice no response to what he said and will naturally repeat that.
The settings for continuous recognition that would work in this case would be:
Continuous Recognition is supported in Voicegain integration for Twilio Media Streams - either TwiML <Stream> or <Connect><Stream> in Twilio Programmable Voice
It is not yet supported in Voicegain Telephony Bot APIs.

Many of our customers have been asking us for help in benchmarking Voicegain speech-to-text recognizer (ASR) on their specific audio files. To make this benchmarking easier we have released a python script that accomplishes just that. With a single command line you can transcribe all audio files from the input directory and compare them against reference transcripts - calculating the WER for each file. You can also do a 2-way comparison of reference vs Voicegain transcript vs Google Speech-to-Text transcript.
The script and the documentation is available at: https://github.com/voicegain/platform/tree/master/utility-scripts/test-transcribe
See our benchmark blog post to give you an idea of what kind of accuracy to expect from the Voicegain recognizer.
Updated: Feb 28 2022
In this blog post we describe two case studies to illustrate improvements in speech-to-text or ASR recognition accuracy that can be expected from training of the underlying acoustic models. We trained our acoustic model to recognize Indian and Irish English better.
The Voicegain out-of-the-box Acoustic Model which is available as default on the Voicegain Platform had been trained to recognize mainly US English although our training data set did contain some British English audio. The training data did not contain Indian and Irish English, except for maybe accidental occurrences.
Both case studies were performed in an identical manner:
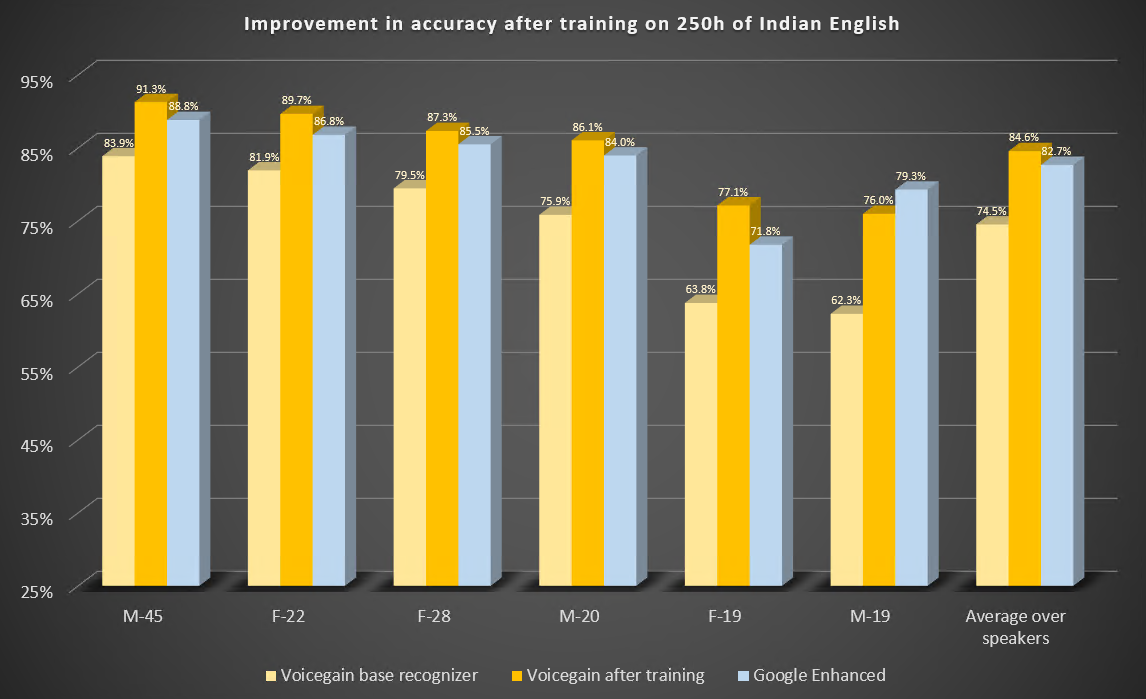
Here are the parameters of this study.
Here are the results of the benchmark before and after training. For comparison. we also include results from Google Enhanced Speech-to-Text.
Some observations:
Here are the parameters of this study.
Here are the results of the benchmark before and after training. We also include results from Google Enhanced Speech-to-Text.
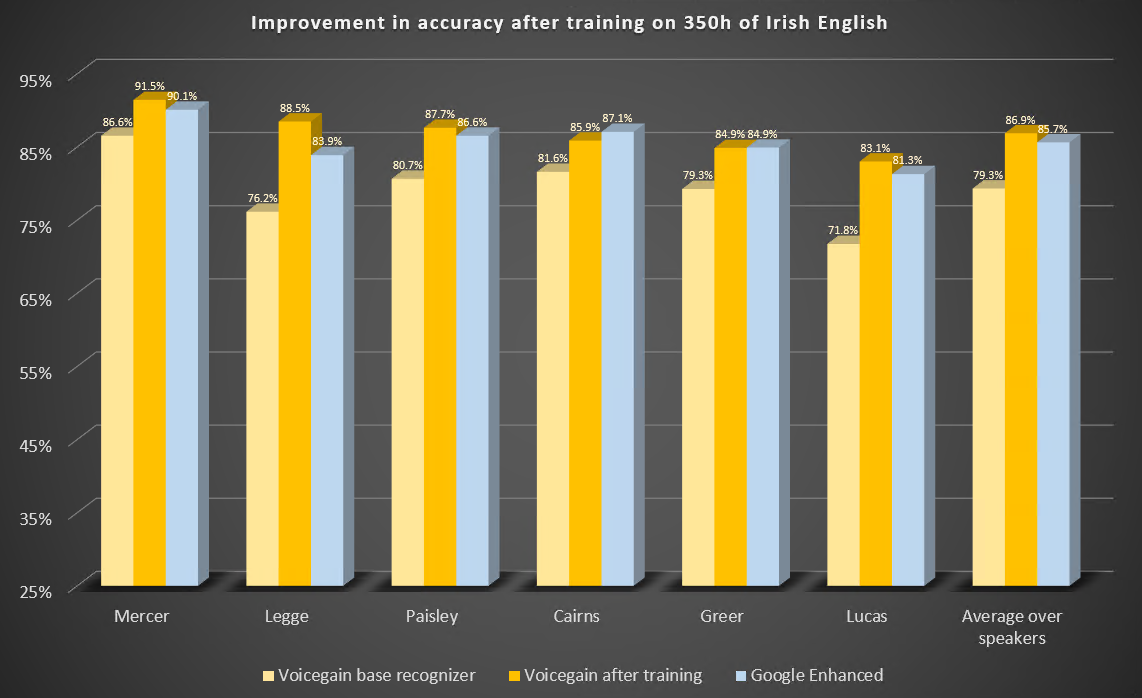
Some observations:
We have published 2 additional studies showing the benefits of Acoustic Model training:
1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click hereto sign up for a developer account and receive $50 in free credits
3. If you want to take Voicegain as your own AI Transcription Assistant to meetings, click here.

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices