
Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
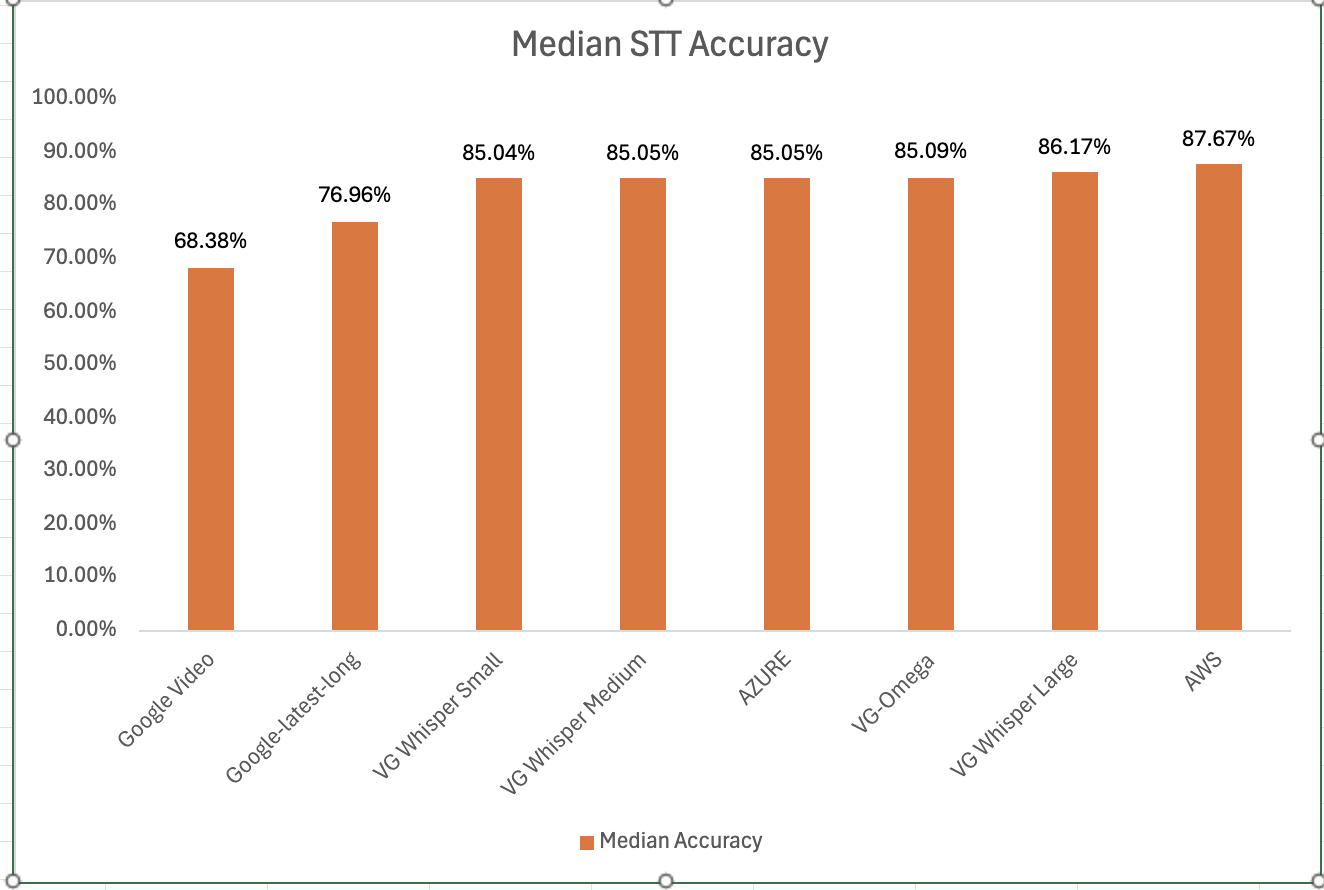
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

In our previous post we described how Voicegain is providing grammar-based speech recognition to Twilio Programmable Voice platform via the Twilio Media Stream Feature.
Starting from release 1.16.0 of Voicegain Platform and API it possible to use Voicegain speech-to-text for speech transcription (without grammars) to achieve functionality like using TwiML <Gather>.
The reasons we think it will be attractive to Twilio users are:
Using Voicegain as an alternative to <Gather> will have similar steps to using Voicegain for grammar-based recognition - these are listed below.
This is done by invoking Voicegain async transcribe API: /asr/transcribe/async
Below is an example of the payload needed to start a new transcription session:
Some notes about the content of the request:
This request, if successful, will return the websocket url in the audio.stream.websocketUrl field. This value will be used in making a TwiML request.
Note, in the transcribe mode DTMF detection is currently not possible. Please let us know if this is something that would be critical to your use case.
After we have initiated a Voicegain ASR session, we can tell Twilio to open Media Streams connection to Voicegain. This is done by means of the following TwiML request:
Some notes about the content of the TwiML request:
Below is an example response from the transcription in case where "content" : {"full" : ["transcript"] } .

We want to share a short video showing live transcription in action at CBC. This one is using our baseline Acoustic Model. No customizations were made, no hints used. This video gives an idea of what latency is achievable with real-time transcription.
Automated real-time transcription is a great solution for accommodating hearing impaired if no sign-language interpreter is available. I can be used, e.g., at churches to transcribe sermons, at conventions and meetings to transcribe talks, at educational institutions (schools, universities) to live transcribe lessons and lectures, etc.
Voicegain Platform provides a complete stack to support live transcription:
Very high accuracy - above that provided by Google, Amazon, and Microsoft Cloud speech-to-text - can be achieved through Acoustic Model customization.

Voicegain adds grammar-based speech recognition to Twilio Programmable Voice platform via the Twilio Media Stream Feature.
The difference between Voicegain speech recognition and Twilio TwiML <Gather> is:
When using Voicegain with Twilio, your application logic will need to handle callback requests from both Twilio and Voicegain.
Each recognition will involve two main steps described below:
This is done by invoking Voicegain async recognition API: /asr/recognize/async
Below is an example of the payload needed to start a new recognition session:
Some notes about the content of the request:
This request, if successful, will return the websocket url in the audio.stream.websocketUrl field. This value will be used in making a TwiML request.
Note, if the grammar is specified to recognize DTMF, the Voicegain recognizer will recognize DTMF signals included in the audio sent from Twilio Platform.
After we have initiated a Voicegain ASR session, we can tell Twilio to open Media Streams connection to Voicegain. This is done by means of the following TwiML request:
Some notes about the content of the TwiML request:
Below is an example response from the recognition. This response is from built-in phone grammar.

Some of the feedback that we received regarding the previously published benchmark data, see here and here, was concerning the fact that the Jason Kincaid data set contained some audio that produced terrible WER across all recognizers and in practice no one would user automated speech recognition on such files. That is true. In our opinion, there are very few use cases where WER worse than 20%, i.e. where on average 1 in every 5 words is recognized incorrectly, is acceptable.
What we have done for this blog post is we have removed from the reported set those benchmark files for which none on the recognizers tested could deliver WER 20% or less. This criterion resulted in removal of 10 files - 9 from the Jason Kincaid set of 44 and 1 file from the rev.ai set of 20. The files removed fall into 3 categories:
As you can see, Voicegain and Amazon recognizers are very evenly matched with average WER differing only by 0.02%, the same holds for Google Enhanced and Microsoft recognizer with the WER difference being only 0.04%. The WER of Google Standard is about twice of the other recognizers.

[UPDATE - October 31st, 2021: Current benchmark results from end October 2021 are available here. In the most recent benchmark Voicegain performs better than Google Enhanced. Our pricing is now 0.95 cents/minute]
[UPDATE: For results reported using slightly different methodology see our new blog post.]
This is a continuation of the blog post from June where we reported the previous speech-to-text accuracy results. We encourage you to read it first, as it sets up a context to better understand the significance of benchmarking for speech-to-text.
Apart for that background intro, the key differences from the previous post are:
Here are the results.

Less than 3 months have passed from the previous test, so it is not surprising to see no improvement on Google and Amazon recognizers.
Voicegain recognizer has how overtaken Amazon by a hair breadth in average accuracy, although Amazon median accuracy on this data set is slightly above Voicegain.
Microsrosoft recognizer has improved during this time period - on the 44 benchmark files it is now on average better than Google Enhanced (in the chart we retained ordering from the June test). The single bad outlier in Google Enhanced results does alone not account for the better average WER on the Microsoft on this data set.
Google Standard is still very bad and we will likely stop reporting on it in detail in our future comparisons.
The audio from the 20-file rev.ai test is not as challenging as some of the files in the 44-file benchmark set. Consequently the results are on average better but the ranking of the recognizers does not change.

As you can see in this chart, on this data set the Voicegain recognizer is marginally better than Amazon in. It has lower WER on 13 out of 20 test files and it beats Amazon in the mean and median values. On this data set Google Enhanced beats Microsoft.
Finally, here are the combined results for all the 64 benchmark files we tested.

On the combined benchmark Voicegain beats Amazon both in average and median WER, although the median advantage is not as big as on the 20 file rev.ai set. [Note that as of 2/10/21 Voicegain WER is now 16.46|14.26]
What we would like to point out is that when comparing Google Enhanced to Microsoft, one wins if we compare the average WER while the other has a better median WER value. This highlights that the results vary a lot depending on what specific audio file is being compared.
These results show that choosing the best recognizer for a given application should be done only after thorough testing. Performance of the recognizers varies a lot depending on the audio data and acoustic environment. Moreover, the prices vary significantly. We encourage you to try the Voicegain Speech-to-Text engine for your application. It might be a better fit for your application. Even if the accuracy is a couple of points behind the two top players, you might still want to consider Voicegain because:
Voicegain launched an extension to Voicegain /asr/recognize API that supports Twilio Media Streams via TwiML <Connect><Stream>. With this launch, developers using Twilio's Programmable Voice get an accurate, affordable, and easy to use ASR to build Voice Bots /Speech-IVRs.
Update: Voicegain also announced that its large vocabulary transcription (/asr/transcribe API) integrates with Twilio Media Streams. Developers may use this to voice enable a chat bot developed on any bot platform or develop a real-time agent assist application.
Voicegain Twilio Media Streams support gives developers the following features:

TwiML <Stream> requires a websocket url. This url can be obtained by invoking Voicegain /asr/recognize/async API. When invoking this API the grammar to be used in the recognition has to be provided. The websocket URL will be returned in the response.

In addition to the wss url, Custom Parameters within <Connect><Stream> command are used to pass information about the question prompt to be played to the caller by Voicegain. This can be a text or a url to a service that will provide the audio.
Once <Connect><Stream> has been invoked, Voicegain platform takes over- it:
BTW, we also support DTMF input as an alternative to speech input.
[UPDATE: you can see more details of how to use Voicegain with Twilio Media Streams in this new Blog post.]
1. On Premise Edge Support: While Voicegain APIs are available as a cloud PaaS service, Voicegain also supports OnPrem/Edge deployment. Voicegain can be deployed as a containerized service on a single node Kubernetes cluster, or onto multi-node high-availability Kubernetes cluster (on your GPU hardware or your VPC).
2. Acoustic model customization: This allows to achieve very high accuracy beyond what is possible with out of the box recognizers. The grammar tuning and regression tool mentioned earlier, can be used to collect training data for acoustic model customization.
On our near-term roadmap for Twilio users we have several more features:
You can sign up to try our platform. We are offering 600 minutes of free monthly use of the platform. If you have questions about integration with Twilio, send us a note at support@voicegain.ai.
Twilio, TwiML and Twilio Programmable Voice are registered trademarks of Twilio, Inc

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices