
Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
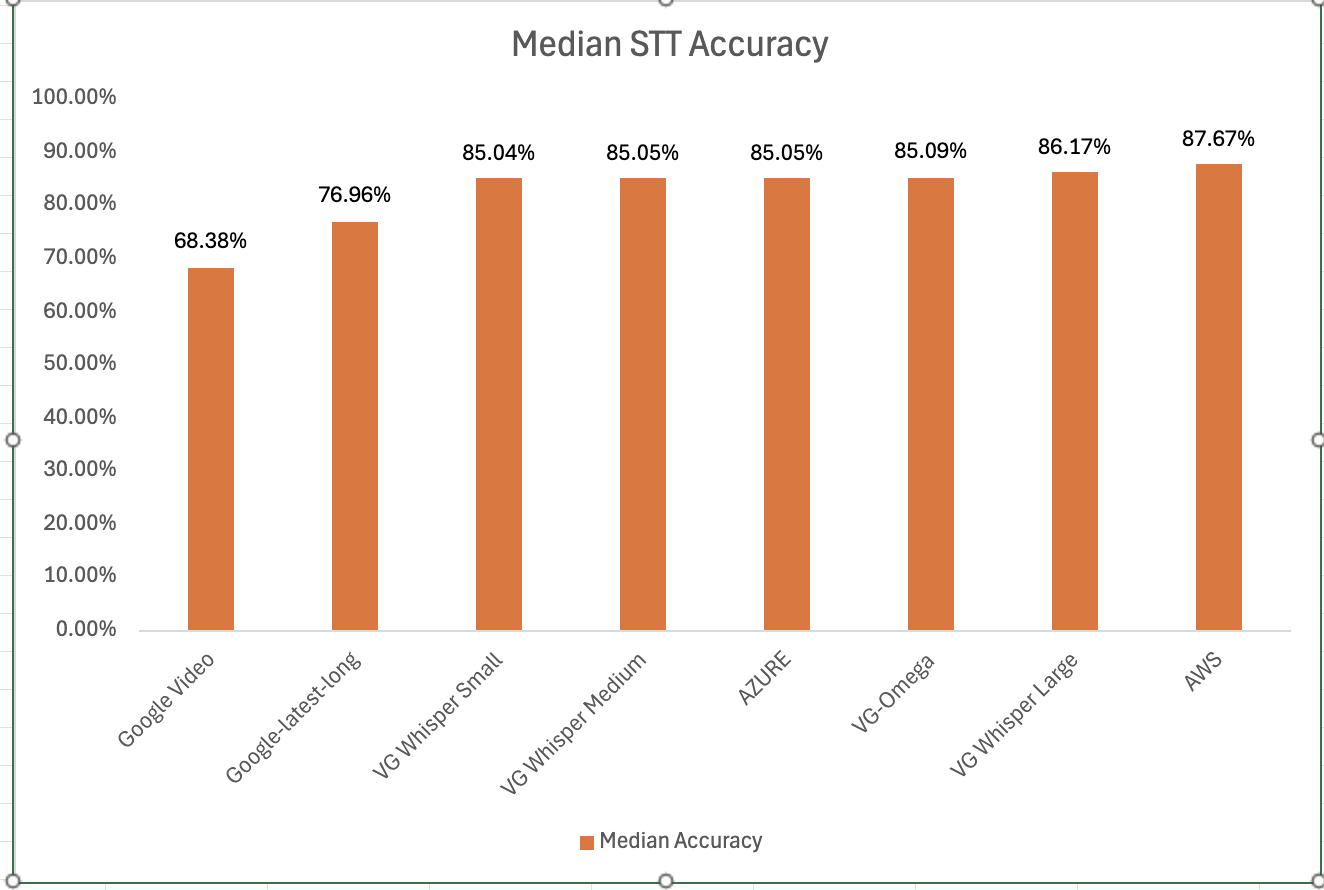
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

Since June 2020, Voicegain has published benchmarks on the accuracy of its Speech-to-Text relative to big tech ASRs/Speech-to-Text engines like Amazon, Google, IBM and Microsoft.
The benchmark dataset for this comparison has been a 3rd Party dataset published by an independent party and it includes a wide variety of audio data – audiobooks, youtube videos, podcasts, phone conversations, zoom meetings and more.
Here is a link to some of the benchmarks that we have published.
1. Link to June 2020 Accuracy Benchmark
2. Link to Sep 2020 Accuracy Benchmark
3. Link to June 2021 Accuracy Benchmark
4. Link to Oct 2021 Accuracy Benchmark
5. Link to June 2022 Accuracy Benchmark
Through this process, we have gained insights into what it takes to deliver high accuracy for a specific use case.
We are now introducing an industry-first relative Speech-to-Text accuracy benchmark to our clients. By "relative", Voicegain’s accuracy (measured by Word Error Rate) shall be compared with a big tech player that the client is comparing us to. Voicegain will provide an SLA that its accuracy vis-à-vis this big tech player will be practically on-par.
We follow the following 4 step process to calculate relative accuracy SLA
In partnership with the client, Voicegain selects benchmark audio dataset that is representative of the actual data that the client shall process. Usually this is a randomized selection of client audio. We also recommend that clients retain their own independent benchmark dataset which is not shared with Voicegain to validate our results.
Voicegain partners with industry leading manual AI labeling companies to generate a 99% human generated accurate transcript of this benchmark dataset. We refer to this as the golden reference.
On this benchmark dataset, Voicegain shall provide scripts that enable clients to run a Word Error Rate (WER) comparison between the Voicegain platform and any one of the industry leading ASR providers that the client is comparing us to.
Currently Voicegain calculate the following two(2) KPIs
a. Median Word Error Rate: This is the median WER across all the audio files in the benchmark dataset for both the ASRs
b. Fourth Quartile Word Error Rate: After you organize the audio files in the benchmark dataset in increasing order of WER with the Big Tech ASR, we compute and compare the average WER of the fourth quartile for both Voicegain and the Big Tech ASR
So we contractually guarantee that Voicegain’s accuracy for the above 2 KPIs relative to the other ASR shall be within a threshold that is acceptable to the client.
Voicegain measures this accuracy SLA twice in the first year of the contract and annually once from the second year onwards.
If Voicegain does not meet the terms of the relative accuracy SLA, then we will train the underlying acoustic model to meet the accuracy SLA. We will take on the expenses associated with labeling and training . Voicegain shall guarantee that it shall meet the accuracy SLA within 90 days of the date of measurement.
1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click here to sign up for a developer account and receive $50 in free credits
3. If you want to take Voicegain as your own AI Transcription Assistant to meetings, click here.

Twilio platform supports encrypted call recordings. Here is Twillo documentation regarding how to setup encryption for the recordings on their platform.
Voicegain platform supports direct intake of encrypted recordings from the Twilio platform.
The overall diagram of how all of the components work together is as follows:

Bellow we describe how to configure a setup that will automatically submit encrypted recordings from Twilio to Voicegain transcription as soon as those recordings are completed.
Voicegain will require a Private Key in a PKCS#8 format to decrypt Twilio recordings. Twilio documentation describes how to generate a Private Key in that format.
Once you have the key, you need to upload it via Voicegain Web Console to the Context that you will be using for transcription. This can be done via Settings -> API Security -> Auth Configuration. You need to choose Type: Twilio Encrypted Recording.

We will be handling Twilio recording callbacks using an AWS Lambda function, but you can use an equivalent from a different Cloud platform or you can have your own service that handles https callbacks.
A sample AWS Lambda function in Python is available on Voicegain Github: platform/AWS-lambda-for-encrypted-recordings.py at master · voicegain/platform (github.com)
You will need to modify that function before it can be used.
First you need to enter the following parameters:
The Lambda function receives the callback from Twilio, parses the relevant info from it, and then submits a request to Voicegain STT API for OFFLINE transcription. If you want, you can modify, in the Lambda function code, the body of the request that will be submitted to Voicegain. For example, the github sample submits the results of transcription to be viewable in the Web Console (Portal), but you will likely want to change that, so that the results are submitted via a Callback to your HTTPS endpoint (there is a comment indicating where the change would need to be made).
You can also make other changes to the body of the request as needed. For the complete spec of the Voicegain Transcribe API see here.
Here is a simple python code that can be used to make an outbound Twilio call which will be recorded and then submitted for transcription.
Notice that:

It has been over 7 months since we published our last speech recognition accuracy benchmark. Back then the results were as follows (from most accurate to least): Microsoft and Amazon (close 2nd), then Voicegain and Google Enhanced, and then, far behind, IBM Watson and Google Standard.
Since then we have obtained more training data and added additional features to our training process. This resulted in a further increase in the accuracy of our model.
As far as the other recognizers are concerned:
We have decided to no longer report on Google Standard and IBM Watson accuracy, which were always far behind in accuracy.
We have repeated the test using similar methodology as before: used 44 files from the Jason Kincaid data set and 20 files published by rev.ai and removed all files where none of the recognizers could achieve a Word Error Rate (WER) lower than 25%.
This time only one file was that difficult. It was a bad quality phone interview (Byron Smith Interview 111416 - YouTube).
You can see boxplots with the results above. The chart also reports the average and median Word Error Rate (WER)
All of the recognizers have improved (Google Video Enhanced model stayed much the same but Google now has a new recognizer that is better).
Google latest-long, Voicegain, and Amazon are now very close together, while Microsoft is better by about 1 %.
Let's look at the number of files on which each recognizer was the best one.
Note, the numbers do not add to 63 because there were a few files where two recognizers had identical results (to 2 digits behind comma).
We now have done the same benchmark 4 times so we can draw charts showing how each of the recognizers has improved over the last 1 year and 9 months. (Note for Google the latest result is from latest-long model, other Google results are from video enhanced.)
You can clearly see that Voicegain and Amazon started quite bit behind Google and Microsoft but have since caught up.
Google seems to have the longest development cycles with very little improvement since Sept. 2021 till very recently. Microsoft, on the other hand, releases an improved recognizer every 6 months. Our improved releases are even more frequent than that.


As you can see the field is very close and you get different results on different files (the average and median do not paint the whole picture). As always, we invite you to review our apps, sign-up and test our accuracy with your data.
When you have to select speech recognition/ASR software, there are other factors beyond out-of-the-box recognition accuracy. These factors are, for example:
1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click here to sign up for a developer account and receive $50 in free credits
3. If you want to take Voicegain as your own AI Transcription Assistant to meetings, click here.

Today, we are really excited to announce the launch of Voicegain Transcribe, an AI based transcription assistant for both in-person and web meetings. With Transcribe, users can focus on their meetings and leave the note taking to us.
Transcribe can also be used to convert streaming and recorded audio from video events, webinars, podcasts and lectures into text.
Voicegain Transcribe is an app accessible from Chrome or Edge Browser and is powered by Voicegain's highly accurate speech recognition platform. Our out-of-the-box accuracy of 89% is on par with the very best.
Currently there are 3 main ways you can use Voicegain Transcribe:

If you join meetings directly from your Chrome or Edge browser (without any downloads or plug-ins), then you can use this feature to send audio to Voicegain. Examples of meeting platforms include Google Meet, BlueJeans, Webex and Zoom.
On a Windows device, browser sharing also works with a client desktop app like Zoom and Microsoft Teams. On a Mac/Apple device, browser sharing support desktop apps.
Voicegain offers a downloadable Windows client app that is installed on the user's computer. This app accesses Zoom Local Recordings and automatically uploads them for transcription to Voicegain Transcribe.
Zoom has two types of recordings - Local Recordings and Cloud Recordings. This app is for Local Recordings - where the recording is stored on the hard disk of the user's computer. To learn more about Zoom local recording click here.
Zoom also allows a separate audio file for each participant's recording. Voicegain App supports upload of these individual participant's audio file so that the speaker labels are accurately assigned to the transcript.
Users may also upload pre-recorded audio files of their meetings, podcasts, calls and generate the transcript. We support over 40 different formats including mp3, mp4, wav, aac and ogg). Voicegain supports speaker diarization - so we can separate speakers even on a single channel audio recording.
Currently we support English and Spanish. More languages are in our roadmap - German, Portuguese, Hindi.
Users can organize their meeting recordings and audio files into different projects. A project is like a workspace or a folder.
Users can save the voice signatures of meeting participants and users so that you can accurately assign speaker labels.
Voicegain can also extract meeting action items, positive and negative sentiment.
Users can also mask - in both text and audio - any personally identifiable information.
We are adding a feature where Voicegain Transcribe can join any meeting by having the user just enter the meeting url and inviting Voicegain Transcribe.
We are also adding a Chrome extension that will make it much easier to record and transcribe web meetings.
By signing up today, you will be signed up on our forever Free Plan - which makes you eligible for 120 mins of Meeting Transcription free every month . Once you are satisfied with our accuracy and our user experience, you can easily upgrade to Paid Plans.
If you have any questions, please email us at support@voicegain.ai

[Updated: 5/27/2022]
In addition to the current support for English, Spanish, Hindi, and German languages in its Speech-to-Text platform, Voicegain is releasing support for many new languages over the next couple of months.
You can access these languages right now from the Web Console or via our Transcribe App or via the API
Upon request we will make these languages available for your testing. Generally, they can be available within hours from receiving a request. Please contact us at support@voicegain.ai
The Alpha early access models differ from full-featured production models in the following ways:
As alpha models are being trained on additional data, their accuracy will improve. We are also working on punctuation, capitalization, and formatting of each of those models.
We will update this post as soon as these languages are available in the Alpha early access program.
Since our language models are created exclusively with End-to-End Deep Learning, we can perform transfer learning from one language to another, and quickly support new languages and dialects to better meet your use case. Don’t see your language listed below? Contact us at support@voicegain.ai, as new languages and dialects are released frequently.

This is a Case Study of training the acoustic model of Deep learning based Speech-to-Text/ASR engine for a Voice Bot that could take orders for Indian Food.
The client approached Voicegain as they experienced very low accuracy of speech recognition for a specific telephony based voice bot for food ordering.
The voice bot had to recognize Indian food dishes with acceptable accuracy, so that the dialog could be conducted in a natural conversational manner rather than having to fallback to rigid call flows like e.g. enumerating through a list.
The spoken response would be provided by provided by speakers of South Asian Indian origin. This meant that in addition to having to recognize unique names, the accent would be a problem too.
The out-of-the box accuracy of Voicegain and other prominent ASR engines was considered too low. Our accuracy was particularly low because our training datasets did not have any examples of Indian Dish names spoken with heavy Indian accents.
With the use of Hints, the results improved significantly and we achieved an accuracy of over 30%. However, 30% was far from being good enough.
Voicegain first collected relevant training data (audio and transcripts) and trained the acoustic model of our deep learning based ASR. We have had good success with it in the past, in particular with our latest DNN architecture, see e.g. post about recognition of UK postcodes.
We used a third party data generation service to initially collect over 11,000 samples of Indian Food utterances - 75 utterances per participant. The quality varied widely, but that is good because we think it reflected well the quality of the audio that would be encountered in a real application. Later we collected additional 4600 samples.
We trained two models:
We also first trained on the 10k set, collected the benchmark results, and then trained on the additional 5k data.
We randomly selected 12 sets of 75 utterances (total 894 after some bad recordings were removed) for a benchmark set and used the remaining 10k+ for training. We plan to share a link to the test data set here in a few days.
We compared our accuracy against Google and Amazon AWS both before and after training and the results are presented in a chart below. The accuracy presented here is the accuracy of recognizing the whole dish name correctly. If one word of several in a dish name was mis-recognized, then it was counted as a failure to recognize the dish name. We applied the same methodology if one extra word was recognized, except for additional words that can easily be ignored, e.g., "a", "the", etc. We also allowed for reasonable variances in spelling that would not introduce ambiguity, e.g. "biryani" was considered a match to "biriyani".
Note that the tests on Voicegain recognizer were ran with various audio encodings:
Also, the AWS test was done in offline mode (which generally delivers better accuracy), while Google and Voicegain tests were done in streaming (real-time) mode.

We did a similar set of tests with the use of hints (we did not include AWS because our test script did not support AWS hints at that time).

This shows that huge benefits can be achieved by targeted model training for speech recognition. For this domain, that was new to our model, we increased accuracy by over 75% (10.18% to 86.24%) as result of training.
As you can see, after training we exceeded the Speech-to-Text accuracy of Google by over 45% (86.24% vs 40.38%) if no hints were used. With the use of hints we were better than Google STT by about 36% (87.58% vs 61.30%).
We examined cases where mistakes were still made and they fell into 3 broad categories:
The first type of problems we think can be overcome by training on additional data and that is what we are planning to do, hoping to eventually get accuracy close to 85% (for L16 16kHz audio). The second type could be potentially resolved by post-processing in the application logic if we return the dB values of the recognized words.
If your speech application also suffers from low accuracy and using hints or text-based language models is not working well enough, then acoustic model training could be the answer. Send us an email at info@voicegain.ai and we could discuss doing a project to show how Voicegain trained model can achieve best accuracy on your domain.

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices