
Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
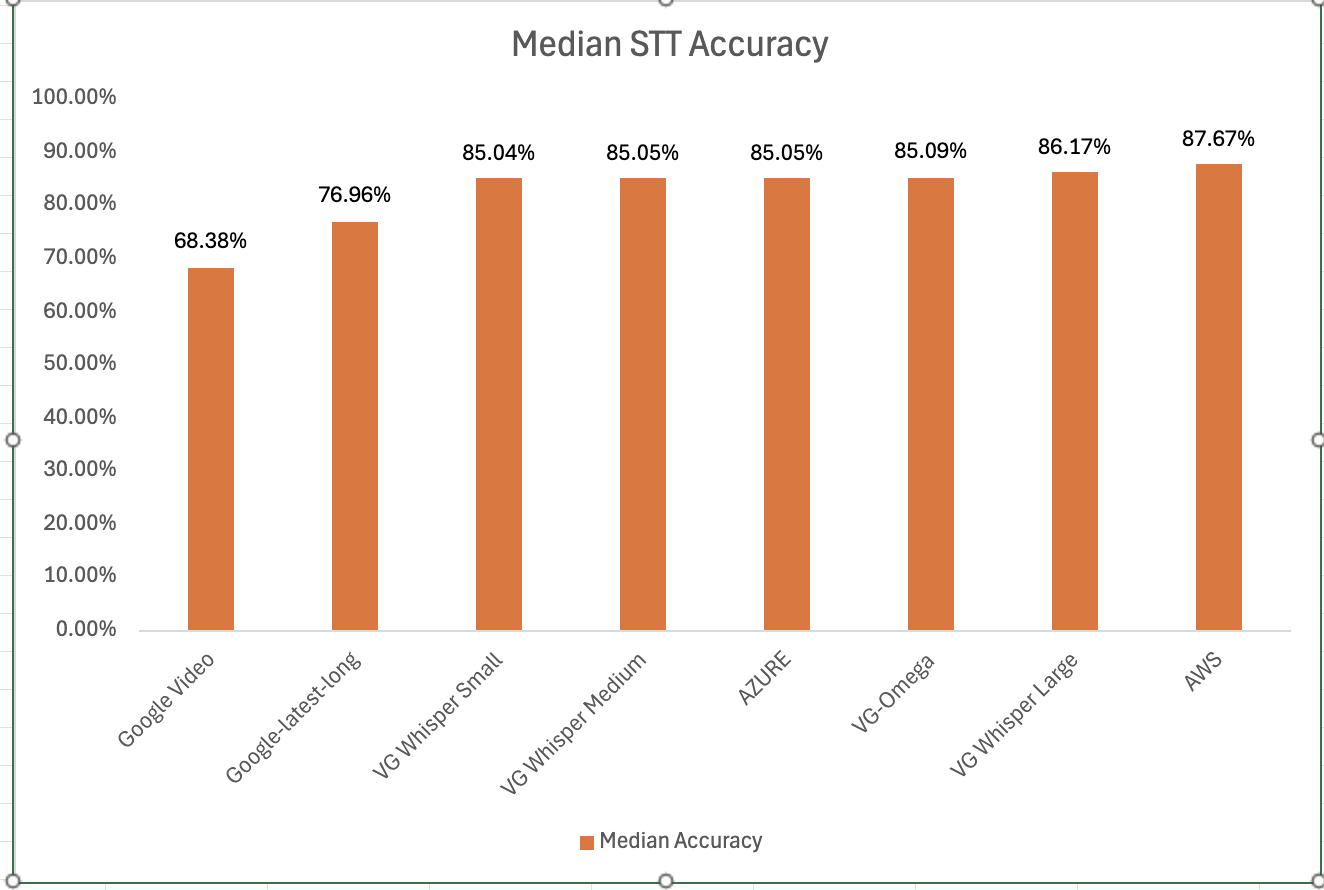
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

This post is the first in a series of posts that compares the performance of Voicegain Speech Analytics against Google and Amazon. This post compares the capabilities and accuracy of recognition/extraction of Named Entities. The Google APIs used for comparison were those under Cloud Natural Language and the Amazon APIs were under AWS Comprehend.
Named Entity Recognition (NER) or extraction of Named Entities is a one of the features of the Voicegain Speech Analytics API. Named Entities Recognition locates and classifies named entities in unstructured text that may be obtained e.g. from the transcription of the audio files. Although there is a lot of overlap between Google, Amazon and Voicegain with respect to the classification categories, there are also some significant differences which are summarized below.

The full spreadsheet linked here shows the named entities extracted by the Voicegain Speech Analytics API and it compares them to the named entity categories available in Google and Amazon Comprehend APIs. Amazon has two NER API: Entity, and PII Entity.
If you look at the spreadsheet you will see that Amazon non-PII Entity API offers little granularity in the named entity categories. For example, it groups a lot of numerical named entities into single QUANTITY category. It groups dates and time (of day) into a single category DATE. On the other hand then PII Entity API has a lot of fine categories related items typically PII-redacted, but it misses a lot of other common entity categories.
Google API seems to cover the usual categories but misses some entities used in call-center application, e.g. CC, SNN, EMAIL>
A category that Voicegain does not support is OTHER. This category which is available in Google and Amazon requires additional application logic to interpret the string that it matches.
We have tested all 4 APIs on a set of call center calls.
The overall results show that Voicegain and Amazon non-PII PAI detect similar named entities (with the caveat that Amazon NER categories are less specific). Compared to these two, Google NER API misses more entities, but it also marks many additional words falling into the OTHER categories (which is generally is not very useful, at least not when analyzing call center calls.
Looking at the Amazon PII Entities we noticed that:
Where Voicegain has a matching entity category for AWS PII Entity it performed same or better.As you see it is difficult to summarize the results because the entities are not directly comparable. If you want to know how Voicegain NER will perform on your data we suggest you test the Voicegain Speech Analytics API which includes NER, keyword, phrase detection, sentiment analysis, etc.
For testing, you have two options:

Voicegain Telephony Bot API allows developers to use Voicegain Speech-to-Text to build Voice Bots or programmable speech IVR using a simple callback API. With latest Voicegain Platform release 1.21.0 it is now possible to establish SIP sessions to Voicegain Telephony Bot API using a simple SIP Invite.
Before release 1.21.0, the only way for voice app developers to use the Voicegain Telephony Bot API was to call the application using phone numbers that were purchased from Voicegain (via the Web Console). However, we have always wanted to allow clients to bring their own carrier or CPaaS platform and this release allows developers to do just that.
At Voicegain our focus is on offering our ASR/Speech Recognition functionality and our full featured Speech-to-Text APIs. We understand developers rely on their CPaaS platforms for a whole host of important features - messaging, emails, conferencing and international coverage. Now, it is possible to integrate Voicegain Telephony Bot API with any CPaaS that supports SIP Invite. You can combine powerful and affordable Speech Recognition features of the Voicegain Platform with the comprehensive API features of these CPaaS platforms
We have already tested SIP Invite extensively on Twilio, SignalWire, and Telnyx platforms. Other similar platforms should also work without issues. We will report any additional platforms that we have explicitly tested in the future.
On Twilio and SignalWire platforms is trivial to establish SIP session to Voicegain. The only thing needed is the <Dial><Sip> command from TwiML or LaML, for example:
Some notes about the above example:
On our github you can find sample code showing how to dial a outbound call and then bridge it to Voicegain SIP:
On Telnyx we tested SIP INVITE using the Telnyx Call Control API. The only functional difference from Twilio and SIgnalWire is that on Telnyx you cannot choose TCP as SIP transport (only UDP is supported).
Here is a sample Python code showing how to dial Voicegain SIP:
The complete code for an AWS Lambda function that dials a number using Telnyx and then bridges it to Voicegain SIP is available here: platform/telnyx-dial-outbound-lambda.py at master · voicegain/platform (github.com)
Our Telephony Bot API is a callback API in similar fashion as TwiML or LaML. The main difference is that it is based on JSON and our functionality is focused on Speech Recognition. You can read more about it in our blog post announcing release of that API back in August.
On out Github you can find an example of a Node.js function on AWS Lambda that demonstrates how to interface Voicegain Telephony Bot API with a RASA NLU bot: platform/examples/voicebot-lambda-vg-rasa at master · voicegain/platform (github.com)
You can also check out our sample python function code on AWS Lambda which shows how to implement more traditional (VoiceXML like) IVRs with the use of Speech grammars on top of our Telephony Bot API: platform/declarative-ivr at master · voicegain/platform (github.com)

Here are all the steps needed to signup for a developer account on the Voicegain Platform. Once you have the account you can access the Web Console and you can find all the info on how to use the Web Console and the APIs on our Zendesk Knowledge Base .
1. Start at console.voicegain.ai/signup
2. Enter your name and email. If you wish you can check the Terms of Service and/or Privacy Policy.
3. On the next page let us know how you learned about Voicegain, how you wan to use Voicegain, and accept Terms of Service.

5. After you click Next, Voicegain will send you an email with the link to the next step. If you do not get the email, please check a Junk Mail folder, and if it is not there, please follow instruction on the page shown below.

6. Once you get the email, click on the Set Password button.

7. You will be directed to a web page where you can set your Voicegain password.

8. After you click (Re)set Password you will be directed to the login page where you can enter your login credentials.


9. On the next page click the right arrow icon next to "Cloud Web Console"

10. This will take you to the home page of the Voicegain Web Console. You can follow the mini tutorial that is available on the home page.

11. Help articles are available under the question mark (?) menu. There also you will find our helpdesk support link. Note, some of the support articles are available only to logged in users while others are public.


You can now test the accuracy of both our realtime and offline speech-to-text by visiting our demo page.
Read out paragraphs of your favorite book, give a speech that inspires, mimic your favorite actor or just play a podcast or YouTube video!
If you are noticing delays in real-time transcription results, they are likely because of resource issues on your computer.
Simply click on the microphone icon to get started. You can either speak or stream audio into your microphone from your browser for a full minute.
You can also play back the audio to make sure that it was indeed streamed to us accurately.
Click on the upload recording icon to get started. You can upload up a mono or stereo recorded file - wav or FLAC - that is up to 15MB in size. If you need to transcribe a larger file, please sign up for a free account.
Drop us an email (support@voicegain.ai) if you have any comments.

[UPDATE - October 31st, 2021: Current benchmark results from end October 2021 are available here. In the most recent benchmark Voicegain performs better than Google Enhanced.]
It has been over 8 months since we published our last speech recognition accuracy benchmark (described here). Back then the results were as follows (from most accurate to least): Microsoft and Google Enhanced (close 2nd), then Voicegain and Amazon (also close 4th) and then, far behind, Google Standard.
We have repeated the test using the same methodology as before: take 44 files from the Jason Kincaid data set and 20 files published by rev.ai and remove all files where the best recognizer could not achieve a Word Error Rate (WER) lower than 20%. Last time we removed 10 files, but this time as the recognizers improved only 8 files had their WER higher than 20%.
The files removed fall into 3 categories:
Some of our customers told us that they previously used IBM Watson, so we decided to add also it to the test.
In the new test, as you can see in the results chart above, the order has changed: Amazon has leap-frogged everyone by increasing its median accuracy by over 3% to just 10.02%, it is now in the pole position. Microsoft, Google Enhanced and Google Standard performed at approximately the same level. The Voicegain recognizer improved by about 2%. The newly tested IBM Watson is better than Google Standard, but lags the other recognizers.
New results put Voicegain recognizer very close to Google enhanced:
However the results for a use case depends on the specific audio - for some of them Voicegain will perform slightly better and for some Google may perform marginally better. As always, we invite you to review our apps, sign-up and test our accuracy with your data.
We have looked at both the Mozilla DeepSpeech and Kaldi projects. We ran our complete benchmark on Mozilla DeepSpeech and found that it significantly trails behind Google Standard recognizer. Out of 64 audio files, Mozilla was better than Google Standard on only 5 files and tied on 1. It was worse on the remaining 58 files. Median WER was 15.63% worse for Mozilla compared to Google Standard. The lowest WER of 9.66% for Mozilla DeepSpeech was on audio from Librivox "The Art of War by Sun Tzu". For comparison, Voicegain achieves 3.45% WER on that file.
Regarding Kaldi we have not benchmarked it yet, but from the research published online it looks like Kaldi trails Google Standard too, at least when used with its standard ASpIRE and LibriSpeech models.
When you have to select speech recognition/ASR software, there are other factors beyond out-of-the-box recognition accuracy. These factors are, for example:
1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click hereto sign up for a developer account and receive $50 in free credits
3. If you want to take Voicegain as your own AI Transcription Assistant to meetings, click here.

Wir freuen uns, die Verfügbarkeit von deutscher Spracherkennung auf der Voicegain-Plattform bekannt zu geben. Es ist die dritte Sprache, die Voicegain nach Englisch und Spanisch unterstützt.
Die Spracherkennungsgenauigkeit des deutschen Modells hängt von der Art des Sprachaudios ab. Im Allgemeinen liegen wir nur wenige Prozent hinter der Genauigkeit zurück, die die Speech-to-Text-Engines von Amazon oder Google bieten. Der Vorteil unseres Spracherkennung ist der deutlich niedrigere Preis sowie die Möglichkeit, kundenspezifische Akustikmodelle zu trainieren. Benutzerdefinierte Modelle können eine höhere Genauigkeit aufweisen als Amazon oder Google. Wir empfehlen Ihnen, unsere Webkonsole und / oder API zu verwenden, um die tatsächliche Leistung Ihrer eigenen Daten zu testen.
Natürlich bietet die Voicegain-Plattform auch andere Vorteile wie die Unterstützung von Edge-Bereitstellung (on-prem) und eine umfangreiche API mit vielen Optionen für die sofort einsatzbereite Integration in z. Telefonieumgebungen.
Derzeit ist unsere Speech-to-Text-API mit dem deutschen Modell voll funktionsfähig. Einige der Speech Analytics-API-Funktionen sind für Deutsch noch nicht verfügbar, z. B. Named Entity Recognition oder Sentiment / Mood Detection.
Das deutsche Modell ist zunächst nur in der Version verfügbar, die die Offline-Transkription unterstützt. Die Echtzeitversion des Modells wird in naher Zukunft verfügbar sein.
Um der API mitzuteilen, dass Sie das deutsche Akustikmodell verwenden möchten, müssen Sie es nur in den Kontexteinstellungen auswählen. Deutsche Modelle haben 'de' im Namen, z. VoiceGain-ol-de: 1
Wenn Sie die deutsche Sprachausgabe verwenden möchten, senden Sie uns bitte eine E-Mail an support@voicegain.ai. Wir werden sie für Ihr Konto aktivieren. Wenn Ihre Anwendung ein Echtzeitmodell erfordert, teilen Sie uns dies bitte ebenfalls mit.

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices