
Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
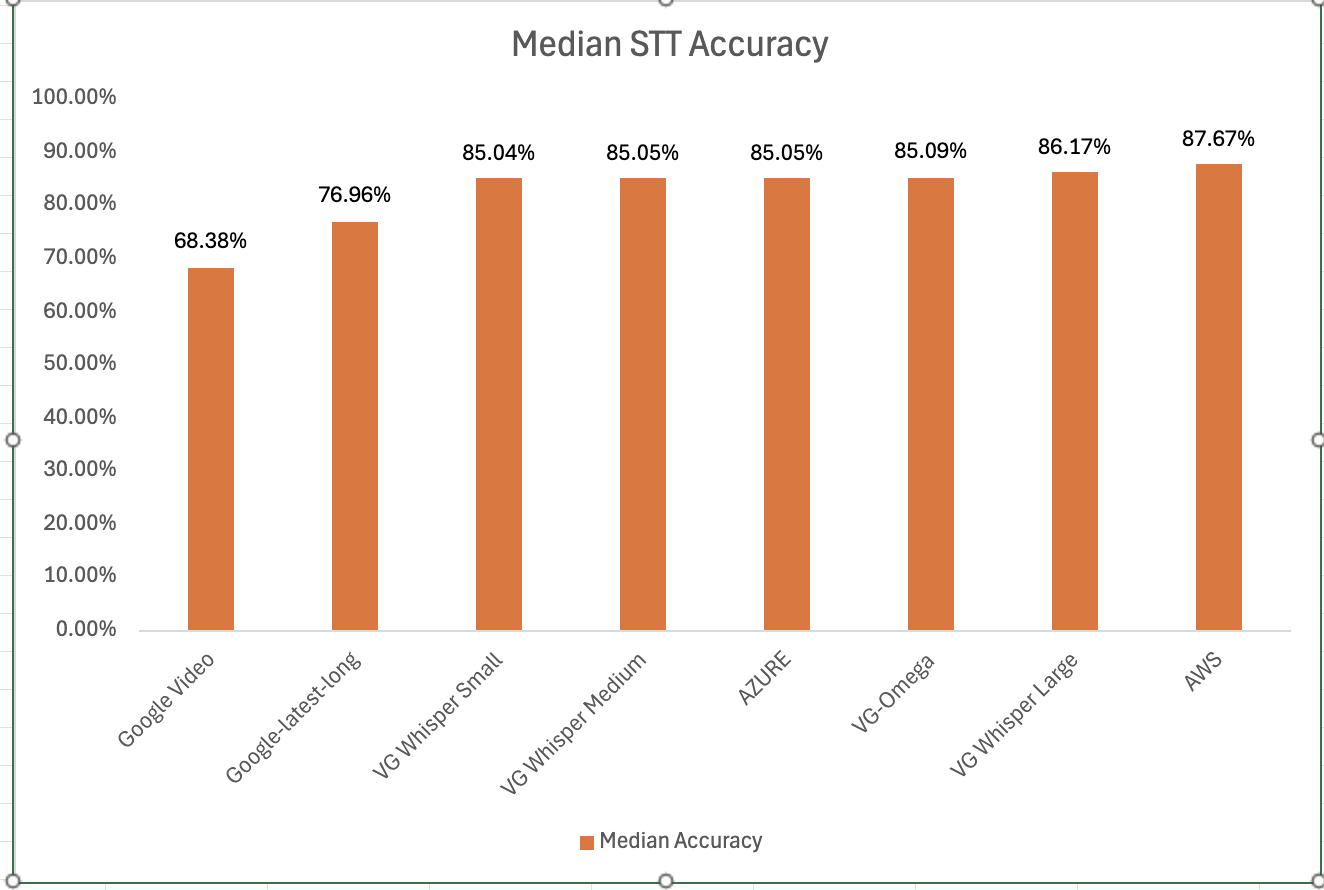
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

It is a common knowledge for AI/ML developers working with speech recognizers and ASR software that getting high accuracy in real-world applications on sequences of alphanumerics is a very difficult task. Examples of alphanumeric sequences are serial numbers of various products, policy numbers, case numbers or postcodes (e.g. UK and Canadian).
Some reasons why ASRs have a hard time recognizing alphanumerics are:
Another reason why the overall accuracy is bad is simply that the errors compound - the longer the sequences the more likely it is that at least one symbol will be misrecognized and thus the whole sequence will be wrong. If accuracy of a single symbol is 90% then the accuracy of a number consisting of 6 symbols will be only 53% (assuming that the errors are independent). Because of that, major recognizers, deliver poor results on alphanumerics. In our interaction with customers and prospects, we have consistently heard about the challenges they have encountered with getting good accuracy on alphanumeric sequences. Some of them use post-processing of the large vocabulary results, in particular, if a set of hypotheses is returned. We used such approaches back when we built IVR systems as Resolvity and had to use 3rd party ASR. In fact, we were awarded with a patent for one of such postprocessing approaches.
While working on a project aiming to improve recognition of UK postcodes we collected over 9000 sample recordings of various people speaking randomly selected valid UK postcodes. About 1/3 of speakers had British accent, while the remaining had a variety of other accents, e.g. Indian, Chinese, Nigerian, etc.
Out of that data set we reserved some for testing. The results reported here are from a 250 postcode test set (we will soon provide a link to this test set on our Github). As of the date of this blog post, Google Speech-to-Text achieved only 43% accuracy and Amazon 58% on this test set.
At Voicegain we use two approaches to help us achieve high accuracy on the alphahumerics: (a) training the recognizer on realistic data sets containing sample alphanumeric sequences, (b) using grammars to constrain the possible recognitions. In a specific scenario, we can use one or the other or even both approaches.
Here is a summary of the results that we achieved on the UK postcodes set.

We used the data set described above in our most recent training round for our English Model and have achieved significant improvement in accuracy when testing on a set of 250 UK postcodes which were not used in training.
Voicegain DNN recognizer has ability to use grammars for speech recognition, a somewhat unique feature among modern speech recognizers. We support GRXML and JSGF grammar format. Grammars are used during the search - they are not merely applied to the result of the large vocabulary recognition - this gives us best possible results. (BTW, we can also combine grammar-based recognition with large vocabulary recognition, see this blog post for more details.)
For UK postcode recognition we defined a grammar which captures all ways in which valid UK postcodes can be said. You can see the exact grammar that we used here.
Grammar based UK postcode recognition gives significantly better results than large vocabulary recognition.
We have come across scenarios where the alphanumeric sequences are difficult to define exhaustively using grammars, e.g. some Serial Numbers. In those cases our recognizer supports the following approach:
We are always ready to help prospective customers with solving their challenges with speech recognition. If your current recognizer does not deliver satisfactory results recognizing sequences of alphanumerics, start a conversation over email at info@voicegain.ai. We are always interested in accuracy.
.png)
This post highlights how Voicegain's deep learning based ASR supports both speech-enabled IVRs and conversational Voice Bots.
This can help Enterprise IT organizations simplify their transition from directed dialog telephony IVR to a modern conversational Voice Bot.
This is because of a very important feature of Voicegain. Voicegain's ASR can be accessed in two ways
1) MRCP ASR for Speech IVR - the traditional way: Voicegain ASR can be invoked over MRCP from a VoiceXML IVR application developed using Speech grammars. Voicegain is a "drop-in" replacement for the ASR used in most of these IVRs.
2) Speech-to-Text/ASR for Bots - the modern way: Voicegain offers APIs integrate with (a) SIP telephony or CPaaS platforms and (b) Bot Frameworks that present a REST endpoint. Examples of bot frameworks supported include Google Dialogflow, RASA and Azure Bot Service.
When it comes to voice self service, enterprises understand that they would need to maintain and operate traditional Speech IVRs for many years.
This is because existing users have been trained over the years and have become proficient with these speech enabled IVRs. They would prefer not having to learn new user interface like Voice Bots if they can avoid it. Also enterprises have made substantial investments in developing these IVRs and they would like to continue to support these IVRs as long as they generate adequate usage.
However an increasing "digital-native" segment of customers demand Alexa-like conversational experiences as it provides a much better user experience compared to IVRs. This is driving substantial interest by enterprises to develop Voice Bots as a long term replacement for IVRs.
Net-net, even as enterprises develop new conversational Voice Bots for the long term; in the near term, they would need to support and operate these IVRs .
ASR: While both Voice bots & IVRs require ASR/Speech-to-Text, the ASRs that support conversational voice bots are different from the ASRs used in directed dialog IVRs. The ASRs that support IVRs are based on HMMs (Hidden Markov models) and and the apps use speech grammars when invoking the ASR. On the other hand, voice bots work with large vocabulary deep learning based STT models.
Protocol: The communication protocols between the ASR & the app are also very different. An IVR App, usually written in VoiceXML, communicates with the ASR over MRCP; modern Bot Frameworks communicate with ASRs over modern web-based protocols like WebSockets and gRPC.
App Stack: The app logic of a directed dialog IVRs is built on VoiceXML compliant application IDE. Popular vendors in this space Avaya Aura Experience Portal (AAEP), Cisco Voice Portal (CVP) and Genesys Voice Portal or Genesys Engage. This article explores this in more detail.
On the other hand, modern Voice bots require Bot frameworks like Google Dialogflow, Kore.ai, RASA, AWS Lex and others. They use modern NLU technology to can extract intent from transcribed text. Bot Frameworks also offer sophisticated dialog management to dynamically determine conversation turns. They also allow integration with other enterprise systems like CRM and Billing.
When it comes to Voice Bots, most enterprises want to "voice-enable" the chatbot interaction logic which is also developed on the same Bot Framework and then integrate with telephony. - so use a phone number to "dial" the chatbot and interact using Speech-to-Text and Text-to-Speech.
The Voicegain platform is the first and currently the only ASR/ Speech-to-Text platform in the market that can support both a directed dialog Speech IVR and a Conversational voice bot using a single acoustic and language model.
Cloud Speech-to-Text APIs from Google, Amazon and Microsoft support large vocabulary speech recognition and can support voice bots. However they cannot be a "drop-in" replacement for the MRCP ASR functionality in directed dialog IVR.
And traditional MRCP ASRs that supported directed dialog IVRs (e.g. Nuance, Lumenvox etc) do not support large vocabulary transcription.
Voicegain offers Telephony Bot APIs to support Bots developers with providing the "mouth" and the "ear" of the Bot.
These APIs are Callback style APIs that an enterprise can can use along with a Bot Framework of its choice.
In addition to the actual ASR, Voicegain also embeds a telephony/PSTN interface. There are 3 possibilities:
1. Integration with modern CPaaS platforms like Twilio, SignalWire and Telnyx With such an integration, callers can now have "dial and talk" to their chatbots over a phone number.
2. SIP INVITE from CCaaS or CPaaS Platform: The Bot Developer can transfer the call control to Voicegain using a SIP INVITE. After the call has been transferred, the Bot Framework can interact using above mentioned APIs. At the end of the bot interaction, you can end the Bot session and continue the live conversation on the CCaaS/CPaaS platform.
3. Voicegain embedded CPaaS: Voicegain has also embedded the Amazon Chime CPaaS; so developers can actually purchase a phone number and start building their voice bot in a matter of minutes.
Essentially, by using Telephony Bot APIs alongside any Bot Framework, an Enteprise can have a Bot framework and an ASR that serves all 3 self service mediums - Chatbots, Voicebots and Directed Dialog IVRs.
To explore this idea further, please send us an email at info@voicegain.ai

[UPDATE 1/23/22: After training on additional data, the Voicegain recognizer now achieves an average WER of 11.89% (an improvement of 0.35%) and a median WER of 10.82% (an improvement of 0.21%) on this benchmark.
Voicegain is now better than Google Enhanced on 44 files (previously 39).
Voicegain is now the most accurate recognizer on 12 of the files (previously 10).
We have additional data on which we will be training soon and will then provide a complete new set of results and comparison.]
It has been over 4 months since we published our last speech recognition accuracy benchmark. Back then the results were as follows (from most accurate to least): Amazon and Microsoft (close 2nd), then Google Enhanced and Voicegain (also close 4th) and then, far behind, IBM Watson and Google Standard.
Since then we have tweaked the architecture of our model and trained it on more data. This resulted in a further increase in the accuracy of our model. As far as the other recognizers are concerned, Microsoft improved the accuracy of their model the most, while the accuracy of others stayed more or less the same.
We have repeated the test using similar methodology as before: used 44 files from the Jason Kincaid data set and 20 files published by rev.ai and removed all files where the best recognizer could not achieve a Word Error Rate (WER) lower than 25%. Note: previously, we used 20% as the threshold, but this time we decided to keep more files with low accuracy to illustrate the differences on that type of files between recognizers.
Only three files were so difficult that none of the recognizers could achieve 25% WER. The two removed files were both radio phone interviews with bad quality of the recording.
As you can see in the results chart above, Voicegain is now better than Google Enhanced, both on average and median WER. Looking at the individual files the results also show the Voicegain accuracy is in most of the case better than Google:
Key observations about other results:
As you can see the field is very close and you get different results on different files (the average and median do not paint the whole picture). As always, we invite you to review our apps, sign-up and test our accuracy with your data.
When you have to select speech recognition/ASR software, there are other factors beyond out-of-the-box recognition accuracy. These factors are, for example:
1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click here to sign up for a developer account and receive $50 in free credits
3. If you want to take Voicegain as your own AI Transcription Assistant to meetings, click here.

You can find the complete code (minus the RASA logic - you will have to supply your own) at our github repository.
The setup allows you to call a phone number and then interact with a Voicebot that uses RASA as the dialog logic engine.
November 2021 Update: We do not recommend S3 and AWS Lambda for a production setup. A more up to date review of various options to build a Voice Bot is described here. You should consider replacing the functionality of S3 and AWS Lambda with a web server that is able to maintain state - like Node.js or Python Flask.
The sequence diagram is provided below. Basically, the sequence of operations is as follows:


The purpose of this blog post is to further elaborate on other posts in which we described various ways you can build a Voice Bot using Voicegain ASR/Speech-to-Text. We also plan to announce a new feature that will soon make Voice Bot development even easier.
Just a quick recap - what is a Voice Bot? A Voice Bot allows users to speak freely and naturally in response to questions asked by the Bot. It can extract multiple "intents" from what a customer says and can respond intelligently. By implementing Voice bots, customers can retire their legacy IVRs and also use a unified Bot platform to power both chatbots and Voice Bots.
It is important to note that Voicegain ASR/Speech-to-Text only provides the "mouth" and the "ear" of the Voice Bot. For building the bot logic and all the back-end integrations (i.e., the brains), a developer has to select a bot framework like Google Dialogflow, RASA, Kore.ai, Microsoft Azure Bot Service, or AWS Lex.
So here are ways you can build a Voice Bot.
This method is described in the blog post: How to build a Voicebot using Voicegain, Twilio, RASA, and AWS Lambda
The important thing to note is that the described setup of using AWS Lambda and S3 to handle the callbacks is for demo purpose only and not ideal for production deployment. The callback server has to be able to handle callbacks from Twilio and from Voicegain and pass information between the two. Because AWS Lambda is stateless the information is being passed in this example via S3 - it makes the end-to-end process slow because of the need for polling. That will not provide a fast response time for your Voice Bot.
For a production-ready setup we suggest replacing AWS Lambda and S3 with a proper web-server that is able to maintain session state - you could use Node.js or Python Flask for that.
This method is described in the blog post: Easy How-To: Build a Voicebot using Voicegain, RASA, and AWS Lambda
This is easier than the method described above. The Voicegain Telephony Bot API uses the Amazon Chime CPaas to provide the functionality otherwise provided by Twilio and this is internally integrated with Voicegain STT API. It uses callbacks, so it needs an intermediate web-service to handle the interaction with a bot platform, e.g. RASA. This web-service may be stateless because Telephone Bot API is capable of maintaining state information.
The example described in the above blog post uses SIP Trunks and phone numbers provided by Amazon Chime which is embedded as part of Voicegain Telephony Bot API. If you would rather retain your CPaaS/Telephony provider (e.g. SignalWire, Twilio, Telnyx, or Bandwidth.com) you can do that and connect to the Telephone Bot API using SIP INVITE. This is described in the blog post: SIP INVITE Voicegain from Twilio, SignalWire, Telnyx CPaaS
This method is described in the blog post: Voicegain announces integration with Audiocodes Voice AI connect.
AudioCodes VoiceAI Connect (VAIC) enables enterprises to connect a bot framework and speech services, such as text-to-speech (TTS) and speech-to-text (STT), to the enterprises’ voice and telephony channels to power Voice Bots, conversational IVRs and Agent Assist use-cases.
AudioCodes provides native integration with Bot Frameworks like Kore.ai, Google Dialogflow and Microsoft Bot Framework.
This setup allows you to directly specify a Voice Bot endpoint instead of specifying a generic http callback destination. The benefit of this is that you do not have to deal with having to provide the callback web-service. Notice that in this setup any back-end requests from your application logic to e.g. data services will now need to be done from the bot platform.
The bot platforms that we already support are RASA and Google Dialogflow. We are currently working on integrating with Microsoft Bot Framework. We hope to have this integration finished in time for the first release of Voicegain-Bot Platform integration. We also plan to very soon work on an integration with Kore.ai.

FreeSWITCH is a very capable telephony platform suitable for building various telephony applications. Some of those applications will rely speech-to-text conversion, for example: ACDs (automatic call distribution), IVRs, Voice-Bots, Real-Time Agent Assist, real-time conference call transcription, call monitoring, etc.
Voicegain Speech-to-Text platform can be used with FreeSWITCH in a variety of ways.
Voicegain STT platform has supported MRCP (Media Resource Control Protocol) for a long time now. Our ASR can be accessed using MRCP and we support both grammar-based recognition (e.g. GRXML) and large-vocabulary transcription. MRCP is a communication protocol designed to connect telephony based IVRs and Voice Bots with speech recognizers (ASR) and speech synthesizers (TTS).
FreeSWITCH can interact with MRCP based recognizers using the included mod_unimrcp module. Voicegain STT has been tested with mod_unimrcp and interfaces with it without problems. You can learn more about using Voicegain STT via mod_unimrcp in this blog post.
Voicegain supports MRCP both in the Cloud and on the Edge (on-prem). We will soon be releasing in OpenSource a recognizer plugin for unimrcp server that will give you even more options in deploying FreeSWITCH with Voicegain and MRCP.
Voicegain provides a Telephony Bot API which is a callback API - similar in style to Twilio TwiML. You can place a call to Voicegain endpoint either using a phone number obtained from Voicegain or using a SIP endpoint unique to your Voicegain application. When a call arrives you will get a web callback and the response you will provide will determine actions that the Voicegain platform will perform, like e.g. play a prompt, recognize speech, detect DTMF, etc.
You can learn more about this API from the following blog posts:
If you have a FreeSWITCH application and you would like to recognize spoken speech you can bridge into Voicegain SIP endpoint and in a callback specify a prompt and the type of speech capture (grammar-based or large vocabulary). Once the recognition finishes you will get a callback and then you can either issue a disconnect command which will transfer call flow back to your Freeswitch app, or you can continue with additional questions and recognitions on Voicegain platform as needed.
Below is an example of a simple interaction with 4 participants:

This is still not Generally Available - please contact us if you are interested in testing.
mod_voicegain will give you capabilities similar to using mod_unimrcp with Voicegain but without the whole overhead of using an MRCP protocol - mod_voicegain talks directly to Voicegain ASR.
mod_voicegain taps into the FreeSWITCH inbound audio stream and sends the audio data to Voicegain ASR in the Cloud or on the Edge. Voicegain ASR processes the audio according to the invocation parameters specified in the data argument. It then communicates the result of transcription or recognition in an Event.
mod_voicegain installs on FreeSWITCH as an app and can be invoked as a such, e.g.:
or from LUA script:
Results will always be returned as a FreeSWITCH event but it is also possible to get the results in a callback to the url specified in callback.uri
The FreeSWITCH event will be of custom type (Event-Name: CUSTOM) and Event-Subclass will be "voicegain_asr_update". The relevant payload will be in the "ASR-Response" field formatted as JSON.
You can read more about mod_voicegain is this Knowledge Base article.
mod_vg_tap has been developed with applications like Real-Time Agent Assist in mind. These apps need access to the audio stream from a FreeSWITCH call but do not otherwise need to interact with FreeSWITCH (unlike IVR and Voice-Bots).
mod_vg_tap installs as an app and has simple commands to start/stop streaming to Voicegain Speech-to-Text engine.
The start command can specify the following destinations:
The results from transcription are generally not returned to a FreeSWITCH app but will be delivered to the destination specified when starting speech-to-text session - the results can be delivered via websocket, polling, or callback.
If you want more information about any of these methods of integrating Voicegain with FreeSWITCH, please email us at support@voicegain.ai.

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices