
Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
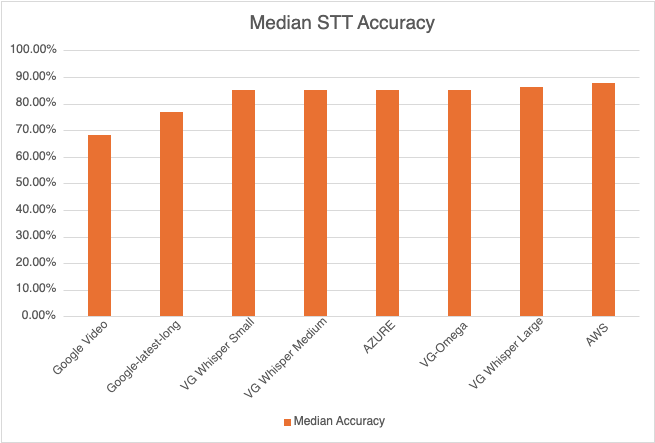
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

One of the previous blog posts described a Voice Bot built using Twilio, Voicegain, RASA, and AWS Lambda. Twilio was used for telephony (phone numbers, SIP Trunking, TwiML for call control) Voicegain provided the ASR/speech recognition, while AWS Lambda was coordinating the actions. The setup works but is involved. The need to pass the speech recognition results via S3 (as Lambda is stateless and does not have memory between function calls) may occasionally cause delays in requests and responses.
Voicegain now integrates with Amazon Chime Voice Connector to offer a pay as you go SIP Trunking service directly from the Voicegain web console. You can also purchase phone numbers and receive inbound calls. Support for making outbound Speech IVR calls is in the works.
Of course, we continue to support developer that use Twilio and SignalWire using simple SIP INVITE - this blog describes how.
The sequence diagram is provided below. It is very simple. Basically, the sequence of operations is as follows:
The sample code for the Lambda function (in python and node.js versions) is available on our github.

1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click hereto sign up for a developer account and receive $50 in free credits

Voicegain Speech-to-Text platform has already for a while supported many of the Twilio features like:
Release 1.26.0 of the Voicegain platform finally offers a full 2-channel support for Twilio Media Streams. This enables real-time transcription of both the inbound and outbound channels at the same time.
Twilio <Stream> command takes a websocket url parameter as a target to which the selected channels are streamed, for example:
The wss url can obtained by starting a new Voicegain real-time transcription session using https://api.voicegain.ai/v1/asr/transcribe/async API. The session part of the request may look like this (notice that two session are started and each will be fed different channel left/right of the audio stream):
We also need to tell Voicegain to take input in TWIML protocol in stereo:
Notice that we can enable audio capture which in addition will give us a stereo recording of the call once the session is complete.
In the response of the start of Voicegain session we get 3 websocket urls:
On our github we provide an example python code that starts a simple outbound Twilio phone call and then transcribes in real-time both inbound and outbound audio.
The sample code illustrates an outbound calling example which is somewhat simpler because there are no callback involved. In a case of an inbound call, the request to Voicegain would have to be done from your Twilio callback function that gets invoked when a new call comes in, otherwise, the rest of the code would be very similar to our github example.
Some of these are already listed on Twilio Media Streams page:
We will be testing the <Stream> functionality on the LaML command language provided by SignalWire platform which is very similar to Twilio TwiML - we will update our blog with the results of those test.
We are also working on a real-time version of our Speech Analytics API. Once complete then all Speech Analytics functionality will be available real-time to users of Twilio and SignalWire platforms.
1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click hereto sign up for a developer account and receive $50 in free credits
3. If you want to take Voicegain as your own AI Transcription Assistant to meetings, click here.

We are excited to announce a new Speech-to-Text (STT) API that works with AudioCodes VoiceAI Connect*. AudioCodes VoiceAI Connect (VAIC) enables enterprises to connect a bot framework and speech services, such as text-to-speech (TTS) and speech-to-text (STT), to the enterprises’ voice and telephony channels to power Voice Bots, conversational IVRs and Agent Assist use-cases.
With this new API, enterprises and NLU/Conversational AI platform companies can leverage the capabilities of AudioCodes VAIC with Voicegain as the ASR or STT engine for their contact center AI initiatives.
The two main use-cases in Contact Centers are (1) building Voice Bots (or voice-enabling a chatbot) and (2) building real-time Agent Assist.
While AudioCodes supports Cloud STT options from large players Microsoft, Google and Amazon, introducing Voicegain as an additional ASR option offers three key benefits to prospective customers. These benefits can be summarized as the 3 As - Accuracy, Affordability and Accessibility.
To get very high STT accuracy, companies now understand the importance of training the underlying acoustic models on application specific audio data. While it is necessary to have a reasonable out-of-the-box accuracy, building voice bots or extracting high quality analytics from voice data requires more than what is offered. Voicegain offers a full fledged training data pipeline and easy-to-use APIs to help speed up the building of custom acoustic models. We have demonstrated significant reduction in Word Error Rates even with a few hundred hours of client specific audio files.
Because AudioCodes VAIC makes it very easy two switch between various STT services, you can easily compare performance of Voicegain STT to any of the other STT providers supported on AudioCodes.
Voicegain offers disruptive pricing compared to the big 3 STT providers at essentially the same out-of-the-box accuracy. Our pricing is 40%-75% lower than the big 3 Cloud Speech-to-Text providers. This is especially important for real-time analytics (real-time agent assist) use case in contact centers as the audio/transcription volumes are very large. In addition to APIs, we also provide a white-label reference UI that contact centers can use to reduce the cost and time-to-market associated with deploying AI apps.
In addition to accessing STT as a cloud service, Voicegain can be deployed onto a Kubernetes cluster in a client's datacenter or in a dedicated VPC with any of the major cloud providers. This addresses applications where compliance, privacy and data control concerns prevent use of STT engines on public cloud infrastructure.
Connecting AudioCodes VAIC to Voicegain is done in 3 simple steps. They are:
1) Add Voicegain as the ASR/STT provider on VAIC. This is done through an API (provided by Audiocodes). In this step, you would need to enter a JWT token from Voicegain web console for authentication (instructions provided below).
2) Enter the web-socket entry URL for Voicegain ASR on VAIC. You can get this URL from Voicegain Web Console (instructions provided below)
3) Configure the Speech Recognition engine settings. This includes picking the right model and having the correct timeout and model sensitivity settings. This is done on the Voicegain Web Console (instructions to sign up provided below)
Please contact your Audiocodes customer success contact for Steps 1 & 2.
You would need to sign up for a developer account on Voicegain Web Console. Voicegain offers an open developer platform and there is no need to enter your credit card. We provide 300 minutes of free Speech-to-Text APIs access every month. You can test out our APIs and check out our accuracy.
After you sign up, please go to Settings-> API Security. The JWT Token required for Step 1 and the API entry URL for Step 2 are provided here.
Also you would need to pick the right acoustic model, set the complete timeout & sensitivity specified in Step 3. Please navigate Settings-> Speech Recognition -> ASR Transcription settings.
If you have any questions please email us at support@voicegain.ai
* VoiceAI connect is a product and trademark owned by AudioCodes.

The entire Voicegain Speech-to-Text/ASR platform and all the associated products - ranging from Web Speech-to-Text (STT) APIs, Speech Analytics APIs, Telephony Bot APIs and the MRCP ASR engine and our logging and monitoring framework - can deployed on "the Edge".
By "Edge" we mean that the core Deep Neural Network based AI models that convert speech/audio into text run exclusively on hardware deployed in a client datacenter. Or after this announcement they can also run on a compute instance in a Virtual Private Cloud. In either case, the Voicegain platform is "orchestrated" using the Voicegain Console which is a web application that is deployed on Voicegain cloud.
On the Edge, the Voicegain platform gets deployed as a container on a Kubernetes Cluster. Voicegain can also be accessed as a Cloud service if clients would not want to manage either server hardware or VPC compute instances.
Voicegain platform has always been deployable in a simple and automated way on hardware in a datacenter. Our clients procure compatible Intel Xeon based servers with Nvidia based GPUs. And they are able to install the entire Voicegain platform a few clicks from the Cloud Portal (see these videos for demonstration).
You can read about the advantages of this Datacenter type of Edge Deployment in our previous blog post. To summarize, these advantages are :
Now these benefits shall also be available for enterprise clients that use a Virtual Private Cloud on AWS to run a portion of their enterprise workloads.

Many enterprises have migrated several enterprise workloads to AWS Cloud infrastructure in order to benefit from the scale, flexibility and ease of maintenance. While moving these workloads to the Cloud, these enterprises largely prefer the private cloud offerings of AWS. e.g., using VPC network isolation, Site-to-Site VPN and dedicated compute instances. For these enterprises, ideally any new workload should be capable of being run inside their AWS VPC. In particular, if an enterprise already has dedicated AWS compute instances or hosts, they could realize all of the above 4 advantages of Edge Deployment by deploying into their dedicated AWS infrastructure.
Recently, anticipating interest of some of our customers we have performed extensive tests of complete deployment of our platform into AWS. Because Voicegain platform is Kubernetes based, there are essentially only two differences from deployment onto local on-premise hardware – these are:
Otherwise, the core of the deployment process is pretty much identical between on premise hardware and AWS VPC.
You can read the details involved in the AWS deployment process on Voicegain's github page.
If you are a developer building something that requires you to add or embed Speech-to-Text functionality (Transcription, Voice Bot or Speech Analytics in Contact Centers, analyzing meetings or sales calls, etc.), we invite you to give Voicegain a try. You can start by signing up for a developer account and use our Free tier. You can also email us at info@voicegain.ai.

This blog post describes how SignalWire developers should integrate with Voicegain Speech-to-Text/ASR based on the application that they are building.
Voicegain offers a highly accurate Speech-to-Text/ASR option on SignalWire. Voicegain is very disruptively priced and one of the main benefits is that it allows developers to customize the underlying acoustic models to achieve very high accuracy for specific accents or industry verticals.
SignalWire developers can fork audio to Voicegain using the <Stream> instruction in LAML. The <Stream> instruction makes it possible to send raw audio streams from a running phone call over WebSockets in near real time, to a specified URL.
Developers looking to just get the raw text/transcript may use the Voicegain STT API to get real time transcription of streamed audio from SignalWire.
For developers that need NLU tags like sentiment, named entities, intents and keywords in addition to the transcript, Voicegain's Speech Analytics API provides those metrics in addition to the transcript.
Applications of real-time transcription and speech analytics include live agent assist in contact centers, extraction of insights for sales calls conducted over telephony, and meeting analytics.
If you want to build a Voice Bot or a directed dialog Speech IVR application that handles calls coming over SignalWire then we suggest using Voicegain Telephony Bot API. This is a web callback API similar to LaML and has instructions or commands specifically helpful in building IVRs or Voice Bots. This API handles speech-to-text, DTMF digits and also plays prompts (TTS, pre-recorded, or a combination).
Your calls are transferred from SignalWire to a Voicegain provided SIP endpoint (based on FreeSWITCH) using a simple SIP INVITE.
Voicegain Telephony Bot API allows you to build two types of applications:
If your application has only a limited need for speech recognition, you can invoke Voicegain STT API only as needed. Every time you need speech recognition in your application, you can simply start a new ASR session with Voicegain either in transcribe (large vocabulary transcription) or recognize (grammar-based recognition) mode. You can use the LAML <stream> command
An example application that could be a voice controlled voicemail retrieval or dictation application where Voicegain recognize API is used in a continuous mode and listens to commands like play, stop, next, etc.
In addition to SignalWire, Voicegain also offers integrations with FreeSWITCH using the built-in mrcp plug-in and a separate module for real-time transcription.
If you are a developer on SignalWire and would like to build an app that requires Speech-to-Text/ASR, you can sign up for a developer account using the instructions provided here.

This blog post will describe 4 ways you can use Telnyx with the Voicegain's Deep Neural Network based Speech-to-Text/ASR platform.
For developers looking to get the raw text/transcript, the Voicegain STT API supports real time transcription of streamed audio from Telnyx.
For conversational AI applications that need NLU tags like sentiment, named entities, intents and keywords in the submitted audio, Voicegain's real-time Speech Analytics API provides those metrics in addition to the transcript.
While both the STT API and the Speech Analytics API support multiple methods to stream audio, Voicegain recommends RTP streaming as the primary method with Telnyx. Developers can stream either 1-channel or 2-channel RTP (the two channels are tied together which is important for some Speech Analytics features).
You can use Telnyx Call Control API to fork the call audio and send it to Voicegain. Call Control API allows you to send either inbound (rx) or outbound (tx) audio or both, this is done using the fork_start command. You can find a complete example of a code needed for real-time transcription of a call here: platform/examples/telnyx/call_control_fork_of_bridged_call at master · voicegain/platform (github.com)
Applications of real-time transcription and speech analytics include live agent assist in contact centers, extraction of insights for sales calls conducted over telephony, and meeting analytics.
If you want to build a Voice Bot or an IVR application that handles calls coming over Telnyx then we suggest using Voicegain Telephony Bot API - this is a callback API similar in style to Twilio's TwiML. This API handles speech-to-text, DTMF digits and also plays prompts (TTS, pre-recorded, or a combination).
Your calls are transferred from Telnyx to Voicegain using a simple SIP INVITE. The SIP INVITE is accomplished using Telnyx Call Control Dial command. You can find a complete example how to do this here: platform/telnyx-dial-outbound-lambda.py at master · voicegain/platform (github.com)
Voicegain Telephony Bot API allows you to build two types of applications:
If your application has only a limited need for speech recognition, you can invoke Voicegain STT API only as needed. Every time you need speech recognition you simply start a new ASR session with Voicegain either in transcribe (large vocabulary transcription) or recognize (grammar-based recognition) mode. The session will return an RTP ip:port to which you can fork your Telnyx audio. You can receive speech-to-text results either over a websocket or via a callback. After you a done with the transcription/recognition session you stop the Telnyx audio fork.
An example application that could be built like that is a voice controlled voicemail retrieval application where Voicegain recognize API is used in a continuous mode and listens to commands like play, stop, next, etc.
Finally, you could use Voicegain Long-Session API (planned to be released later in 2021). This API allows you to establish single long session that takes an ongoing stream of inbound audio from Telnyx (via fork command). Once the session is established you can issue commands for transcription or recognition. They would return results upon finding a speech endpoint or when you explicitly stop them. After processing the results you could issue additional commands on the same Voicegain session.
In addition to returning recognition results, Long-Session STT API returns important events, like e.g. start-of-speech that allows you to implement proper barge-in behavior.
Using this API you could build your own Voice Bot just like the Voice Bots from #2, but you could have more control over your Telnyx session, e.g. you could use conference commands.

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices