
Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
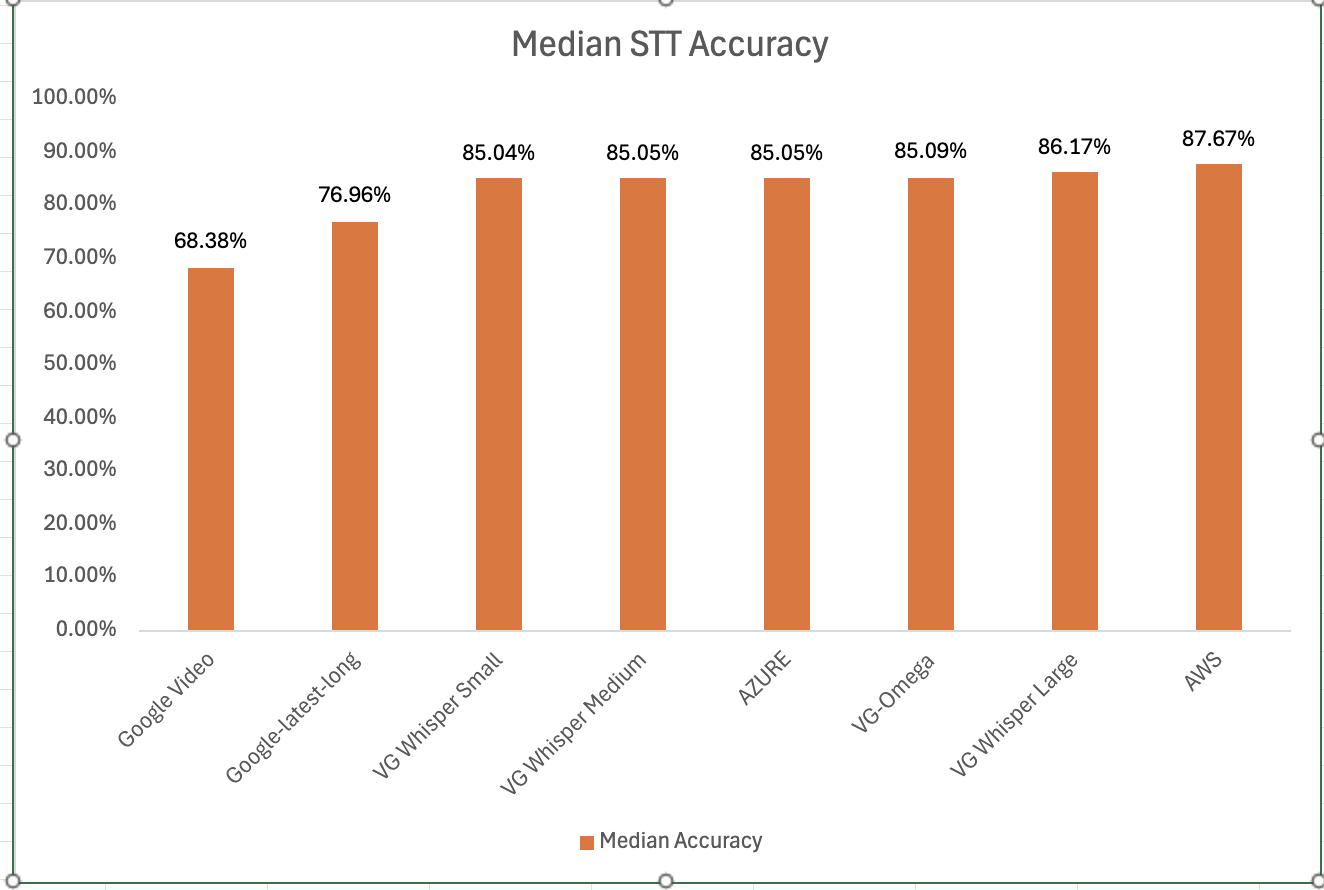
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

Senior leadership teams at most global contact center outsourcers are constantly under pressure. They need to have a laser like focus on key metrics, SLAs and people to manage their businesses. They are increasingly managing a global distributed business that is both labor intensive and technology intensive. And they have to do all of this with increasingly tight margins.
Despite being measured on metrics like CSAT and NPS, a lot of the value that an outsourcer delivers to its clients is often hard to quantify. And too often the price realized by the outsourcer does not capture the value and quality an outsourcer provides.
In this article I would like to propose two new innovative ideas that can help Contact Center BPOs pivot into new SaaS (Software-as-a-Service) revenues.
Both these offerings can be offered to the clients using a Software-as-a-Service (SaaS) based business model in conjunction with the traditional agent side of the business.
Both these SaaS offerings leverage some of the key strengths that BPOs have: Deep domain expertise, in depth understanding of customer issues and technology infrastructure that leverages both
Contact centers have a treasure trove of audio data. Every day associates are handling thousands of calls across a wide variety of topics. While outsourcers use legacy speech analytics vendors, the traditional use has been to analyze a sample of calls to assist in the Quality Assurance function. Net-net, it is viewed as a cost center both for the outsourcers and their clients.
However there is a massive untapped opportunity to mine and extract insights from such audio data for uses well beyond quality assurance. Such insights may be relevant to stakeholders in Product and Marketing teams of the clients. This can open up new non-traditional product and marketing budgets for BPOs.
Outsourcers have an in-depth deeper understanding of current topics that customers are calling about. They have unique and current insights into which categories of calls are actually driving volumes. With the right tools, methodologies and personnel, outsourcers can build and offer new innovative speech self service applications that may automate parts of calls. With the right technologies, outsourcers can move seamlessly between agent assisted calls and automated self-service interactions.
The foundation for these SaaS offerings are modern Deep Neural Network (DNN) based Speech to Text platforms.
The old speech to text were technologies were based on traditional statistical models (called HMMs and GMMs). They were limited in their ability to train on specific industry jargons and accents. But a DNN based platform has the following advantages
For more info, please contact us at info@voicegain.ai.

[UPDATE - October 31st, 2021: Current benchmark results from end October 2021 are available here. In the most recent benchmark Voicegain performs better than Google Enhanced.]
That is the question that we are frequently asked by our potential customers. Often we answer "that depends" and we get a feeling that the other side thinks "must be really bad if they do not give a straight answer". However, "that depends" is really the right answer. Accuracy of automated speech recognition (ASR) depends on the audio in many ways and the effect is not small. Basically, accuracy can be all over the place depending on factors like:
Because the accuracy or Word Error Rate questions are somewhat meaningless without specifying the type of speech audio, it is important to do testing when choosing a speech recognizer. As a test set, one would choose a set of audio files, that accurately represent the spectrum of the speech that will be encountered by the recognizer in the expected use cases. For each speech audio file from the set one would obtain a gold/reference transcript that is 100% accurate. After that, things can be automated -- transcribe each file on the recognizers being evaluated, compute WER against the reference for each of the generated transcripts, and collate the results. The combined results will present a clear picture of how the recognizers perform on the specific speech audio that we care about. If you are going to repeat this process often, e.g., to evaluate new candidates on the recognizer marker, it is good to standardize the test set, basically creating a repeatable benchmark that can be referenced in the future.
The benchmark results that we are presenting here are somewhat different than the use-case driven tests or benchmarks. Because we are building a general recognizer for an unspecified use case, we intentionally decided to use a very broad set of audio files. Rather than collecting the test files ourselves, we decided to use the data set described in "Which Automatic Transcription Service is the Most Accurate? — 2018" from September 2018 by Jason Kincaid. The article presents a comparison of Speech Recognizers from various companies using a set of 48 YouTube videos (taking 5 minutes of audio from each of the videos). By the time we decided to do a retest of Jason's benchmark, 4 videos were no longer accessible, so our benchmark presented here uses data from only 44 videos.
We compared the results presented by Jason to the results from the big 3 - Google, Amazon, and Microsoft - recognizers as of June 2020. Of course, we also included our Voicegain recognizer, because we wanted to see how we stacked against those. All the tested recognizers use Deep Neural Networks. The Voicegain speech recognizer ran on the Google Cloud Platform using Nvidia T4 GPUs. All recognizers were run with default settings and no hints nor user language models were used.
It is important to mention that none of the benchmark files are included in the training set that Voicegain uses. Neither is other audio from the speakers from the benchmark files, nor the same content but spoken by other speakers.
Again, the best recognizer is not the right question, because it all depends on your actual speech audio it is used on. But the key results from testing on the 44 files are as follows:
Here are our thoughts and some details:
We welcome anyone to test our platform and see how it performs on speech audio types that matter for your use cases.
We have Open Sourced the key component of our benchmark suite, the transcribe_compare python utility. It is available here: https://github.com/voicegain/transcription-compare under MIT license.
It is useful for automatic benchmarking but it can also output data to an html file which can be viewed in a web browser. We use it often this way to do a manual review of the transcription errors or differences in errors between two recognizers or recognizer versions.
If you are building an app that requires transcription, sign up today for a developer account and get $50 in free credits (~5000 minutes of platform use). You can check out our accuracy add test our APIs. Instructions to sign up for a developer account are provided here.
3. If you want to make Voicegain your own AI Transcription Assistant, click here. You can take Voicegain to meetings, webinars, talks, lectures and more.
We are still in the middle of extensive data collection effort and the training is not over yet. We are seeing continuing improvement in our recognizer, with the new improved versions of the acoustic model deployed to production about twice a month. We will report updated benchmark results on our blog in a few months.
We have another blog post planned that is going to quantify the benefit one can expect from using additional user data to train the acoustic model used in the recognizer. We have selected a large data set with a very specific English accent that currently has higher WER. We will report on the impact on WER of training on such a data set. We will quantify the improvement based on the size of the data set and the duration of training.
Voicegain provides easy to use tools that allow users to build their own custom acoustic models. This upcoming post will provide a clear insight as to what improvements to expect and how much data is needed to make a difference in reducing WER.
If you have any questions regarding this article or our platform and recognizer you can contact us at info@voicegain.ai

The video below shows an example of Voicegain Live Transcribe used to provide transcription for an event streamed over video.
Here are some details about this particular setup:

Current speech-to-text enterprise market can be divided into 3 distinct groups of players. Note, that we are focusing here on speech-to-text platforms rather than complete end-user products (so we do not include consumer products like Dragon NaturallySpeaking, etc.)
We consider ourselves as as one of the new players as we started working on our own DNN-based speech-to-text engine at the end of 2016. However, we have been working with old style ASRs since 2006 and as a result we knew very well limitations of those. That was what motivated us to develop ASRs of our own.
We are also very familiar with employing ASRs in real-world large volume applications so we know which features the users of ASRs want - be it developers who build the applications, or IT personnel that has to host and maintain them.
All of this guided us in decisions we made when developing our speech-to-text platform.
Below we list what we think are 4 key differentiators of our speech-to-text platform compared to competition. Note that the competitive field is pretty broad, and we consider a particular feature a differentiator if it is not a common feature in the market.
By, Edge Deployment we mean a deployment on customer premises (datacenter) or on VPC. Moreover, the deployment is fully orchestrated and managed from the Cloud (for more information see our blog post about Benefits of Edge Deployment). The aspect of orchestration and built-in management makes it essentially different from the old ASRs which were also deployed on-prem and required Support Contracts do deploy them successfully and to maintain them over time.
We think that Edge Deployment is critical for a speech-to-text platform which is to replace many of the old ASRs in their applications.
Over the years when working with ASRs we noticed that there were cases where the ASR would show consistently higher error rates. Usually, this was related to IVR calls coming from customers in regions of the country with distinct accents.
In some of our use cases so far, ability to customize models has allowed us to reduce WER very significantly (e.g. from 8% WER to 3%).
We are currently working on a rigorous experiment where we are customizing our model to support Irish English. We plan to report in detail on the results in April.
Voicegain speech-to-text platform was developed specifically with IVR use cases in mind. Currently the platform supports the following 3 IVR uses cases, and we are working on adding conversational NLU later this year.
a) ASR with support for legacy IVR Standards
In order to make our speech-to-text engine an attractive solution for replacement of old ASRs, we implemented it to support legacy standards like MRCP and GRXML. That support is not a mere add-on, simply tagging a Web API on the back of an MRCP server, but is more integral - our core speech-to-text engine directly interprets a superset of MCRP protocol commands.
We also support GRXML and JSGF grammars - via MRCP, in IVR callbacks, and over Web API.
When used with grammars, big advantage of Voicegain recognizer is that at the core it is a large vocabulary recognizer. Grammars are used to do constrain the recognized utterances to facilitate semantic mapping, but the recognizer can also recognize Out-of-Grammar utterances, which opens new possibilities for IVR tuning.
b) Web-hook IVR Support (without VXML)
Flow-based IVR systems have traditionally been built using two approaches - (i) either having the dialog interactions interpreted on a VXML platform (VXML browser), or (ii) using webhooks invoking application logic running on standard web back-end platforms (examples of the latter are offerings of e.g. Twilio, Plivo, or Tropo).
Our platform supports webhook style IVRs. Incoming calls can be interfaced via standard telephony SIP/RTP, and the IVR dialog can be directed from any platform that implements web-hooks (e.g. Node.js, Django)
c) Enabling IVRs that use chatbot back-end
Many companies have invested significant effort into building their text based chatbots rather than using products like Google Dialogflow. What Voicegain platform provides is an easy way to deploy the existing chatbot logic on a telephony speech channel. This takes advantage of our platform's webhook-ivr IVR support and can feed real-time text (including multiple alternatives) to a chatbot platform. We also provide audio output either via TTS or prerecorded clips.
Because IVR has always been our focus, we built our Acoustic Models to support low latency real-time speech-to-text (both continuous large vocabulary and with context-free grammars). We also focused on convenient ways to stream audio into our speech-to-text platform, and to consume the generated transcript.
One of our products is Live Transcribe which allows for real-time transcription (with just few seconds delay) which is then broadcast over websockets and can be consumed on provided web clients. This opens possibility to do live speaker transcription with uses cases that may include conferences, lectures, etc. making these events easier to participate by hearing impaired audience members.

In this post we show in three steps what is needed to run your first transcription using Voicegain API.
We assume that you already signed up for Voicegain account and logged into the portal.
Main reason to create new Context is to establish new authentication realm. Access to each Context can be separately controlled, so it is easy to disable access to certain Context without affecting other Contexts.
Contexts are also used for specifying default ASR settings.
You can create a new Context from the Context Dash

Voicegain APIs use JWT (JSON Web Tokens) to identify and authenticate the account making the request. In order to make API requests you need to generate a JWT which can easily be done from the portal.

Below is the complete input and output from curl command that submits a Web API request to Voicegain Synchronous Speech-to-Text API https://api.voicegain.ai/v1/asr/transcribe
In this case, the audio to be transcribed was retrieved from a URL. Audio can alternatively also be submitted in-line (within request).
Note that synchronous transcription has audio length limit of 60 seconds. Longer audio requires use of asynchronous transcription API.
For asynchronous transcription requests it is possible to stream the audio, e.g. via websocket. You can see some of Voicegain API documentation at: https://www.voicegain.ai/api

There is no denying that services available in the Cloud have significant benefits and is hence a popular choice. That is why Voicegain Speech-to-Text Platform is available both in the Cloud and at the Edge. The key benefits of accessing Voicegain as a Cloud services are:

Before we discuss the benefits of Edge Deployment let's define what we mean by it.
Edge Computing for Speech-to-Text services has many advantages:
You may ask - what about the benefits of the Cloud, mentioned upfront? Do I get some of these with the Edge Deployment?
The answer is (qualified) "yes", and specifically:

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices