
Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
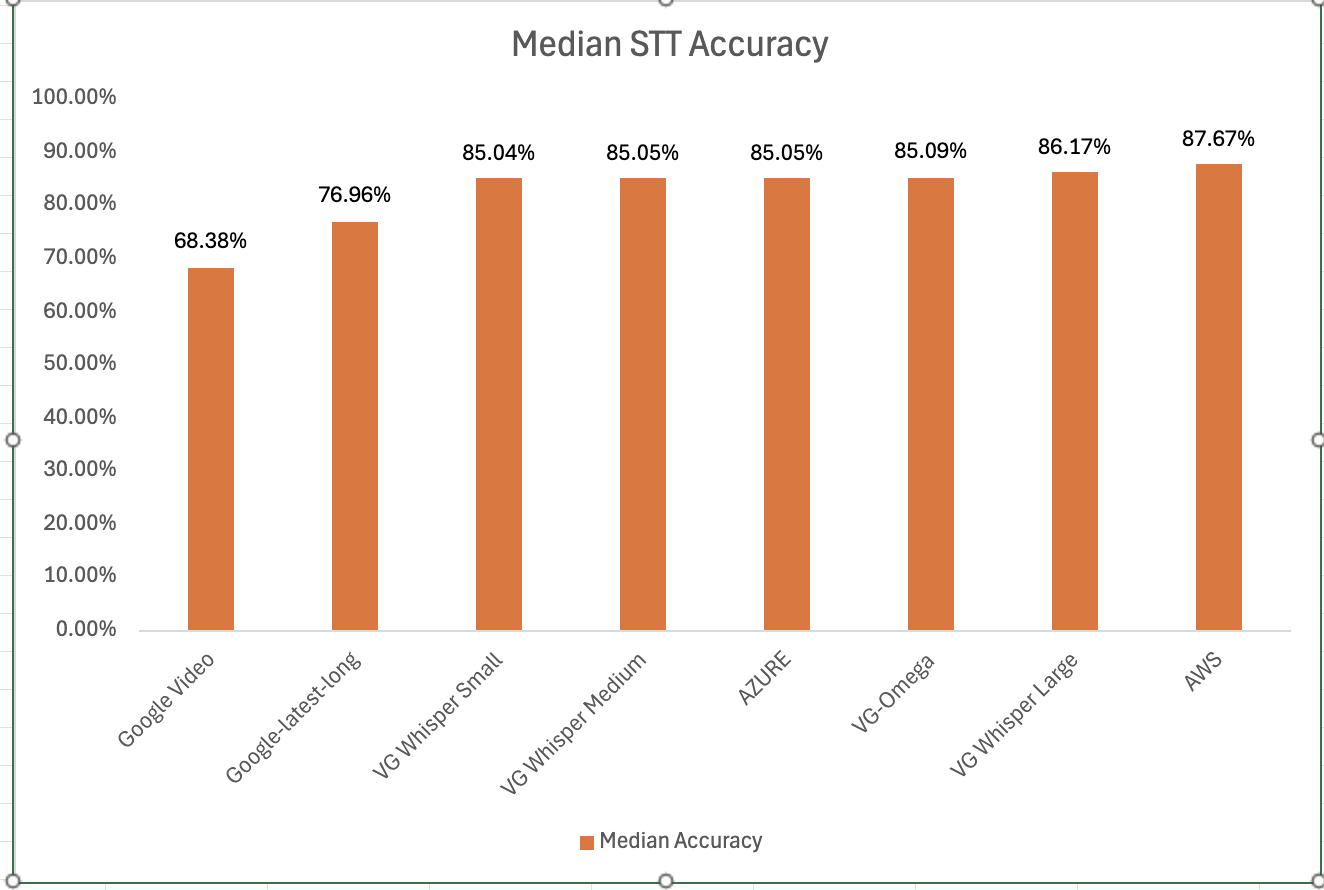
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

We are pleased to announce availability of German Speech-to-Text on the Voicegain Platform. It is the third language that Voicegain supports after English and Spanish.
The recognition accuracy of the German model depends on the type of speech audio. Generally, we are just a few % behind the accuracy offered by the Speech-to-Text engines of the larger players (Amazon, Google, etc). The advantage of our recognizer is its affordability, ability to train customized acoustic models and deploy it in the datacenter or VPC. Custom models can have accuracy higher than that of Amazon or Google. We also offer extensive support for integrating with telephony.
We encourage you to sign up for a developer account and use our Web Console and/or our APIs to test the real-life performance on your own data.
Currently, our Speech-to-Text API supports the German Model. Currently the German Model supports off-line transcription. Real-time/Streaming version of the Model will be available in the near future.
To use the German Acoustic Model in Voicegain Web Console, select "de" under Languages in the Speech Recognition settings.

Voicegain STT platform has supported MRCP (Media Resource Control Protocol) for a long time now. Our ASR can be accessed using MRCP and we support both grammar-based recognition (e.g. GRXML) and large-vocabulary transcription. MRCP is a communication protocol designed to connect telephony based IVRs and Voice Bots with speech recognizers (ASR) and speech synthesizers (TTS).
Previously we tested connecting to Voicegain using MRCP from VXML platforms like Dialogic PowerMedia XMS or Aspect Prophecy. We had not tested connecting from FreeSWITCH, a popular open source telephony platform, using its MRCP plugin mod_unimrcp.
We are pleased to announce that Voicegain platform works out-of-the box with mod_unimrcp, the MRCP plugin for FreeSWITCH. However, getting the mod_unimrcp plugin to work on FreeSWITCH is not particularly trivial. Here are some pointers to help those who would like to use mod_unimrcp with our platform.
There are currently 2 options to do this. We plan to add a third option very soon
Also, the current TTS option accessible over MRCP are not great. Our focus has been on the use of prerecorded prompts for IVRs and Voice Bots. We plan to shortly allow developers to access the Google or Amazon TTS.
mod_unimrcp does not get built by default when you build FreeSWITCH from source. To get it built you need to enable it in build/modules.conf.in by uncommenting this line: #asr_tts/mod_unimrcp
After the build, before starting FreeSWITCH you will need to:
Here is an example MRCP v2 profile for connecting to Voicegain MRCP:
Here are some additional notes about the configuration file:
Here is an example of how to play a question prompt and to invoke the ASR via mod_unimrcp to recognize a spoken phone number:
What this example does is:
The result of the recognition is a string in XML format (NLSML). You will need to parse it to get the utterance and any semantic interpretations. NLSML result also contains confidence.
The normal command "play_and_detect_speech" holds onto ASR session until the end of the call - this makes subsequent recognitions more responsive, but you are paying for the MRCP session. You can also use this command "play_and_detect_speech_close_asr" to release ASR session immediately after recognition.
If you have any questions about the use of Voicegain ASR via MRCP please contact us at: support@voicegain.ai
On our roadmap we have a mod_voicegain plugin for FreeSWITCH which will bypass the need for mod_unimrcp and unimrcp server and will be talking from FreeSWITCH directly to the Voicegain ASR using gRPC.

As pandemic forces Contact Centers to operate with work-from-home agents, managers are increasingly looking to real-time speech analytics to drive improvements in agent efficiency (via reduction in AHT) and effectiveness (improvements in FCR, NPS) and achieve 100% compliance.
Before the pandemic, Contact Center managers relied on a combination of in person supervision and speech analytics of recorded calls to drive improvements in agent efficiency and effectiveness.
However the pandemic has upended everything. It has forced contact centers to support work-from-home agents from multiple locations. Team Leads who "walked the floor" and monitored and assisted agents in realtime are not available any more. The offline Speech Analytics process - which is still available remotely - is limited and manual. A Call Coach or a QA Analyst coaches an agent manually using a sample 1-2% of the calls that have been transcribed and analyzed.
There is a now an urgent need to monitor and support agents real-time and provide them all tools and support that they had while they worked in their offices.
Real-time Agent Assist is the use of Artificial Intelligence - more specifically Speech Recognition and Natural Language Processing - to help agents real-time during the call in the following ways.
Real-time Agent Assist can reduce AHT by 30 seconds to 1 minute, improve FCR by 3-5% and improve NPS/CSAT.
What does it take to implement Real-time Agent Assist?
Real-time agent assist involves the realtime transcription of the Agent and Caller Interaction and extracting keywords, insights and intents from the transcribed text and make it available in a user-friendly manner to both the Agents and also the team-leads and supervisors.
There are 4 key steps involved:
At Voicegain, we make it really easy to develop real-time agent assist applications . Sign up to test the accuracy of our real-time model.

Voicegain platform makes it easy to build IVRs for simple outbound calling applications like: surveys (Voice-of-Customer, political, etc), reminders (e.g. appointments, payments due), notifications (e.g. school closure, water boil notice), and so on.
Voicegain allows developers to use the outbound calling features of CPaaS platforms like Twilio or SignalWire with the speech recognition and IVR features of the Voicegain platform. All you need is this simple piece of code to make an outbound call using Twilio and connect it to Voicegain for IVR.
Voicegain provides a full featured Telephone Bot API. It is a webhook/callback style API that can be used in similar way you would use Twilio's TwiML. You can read more about it here
However, in this post, we describe an even simpler method to build IVRs. We allow developers to specify the Outbound IVR call flow definitions in a simple YAML format. We also provide a python script that can be easily deployed on AWS Lambda or on your web-server to interpret this YAML file. The complete code with examples can be found on our github. It is under MIT license so you can modify the main interpreter script to your liking. You might want to do it e.g. to make calls to external webservices that your IVR needs.
In this YAML format, an IVR question would be defined as follows:
As you can see, this is a pretty easy way to define an IVR question. Notice also that we provide a built-in handling for the NOINPUT and NOMATCH re-prompts, as well as the logic for confirmations. This greatly reduces the the clutter in the specification as those flow scenarios do not have to be handled explicitly.
The questions support either use of grammars to map responses to semantic meaning, or they can alternatively simply capture the response using a large vocabulary transcription.
Prompts are played using TTS or can be concatenated from prerecorded clips.
Because this is built on top of Voicegain Telephone Bot API it comes with full API access to the IVR call session. You can obtain details, including all the events and responses, of the complete session using the API. This includes the 2-channel recording plus also full transcription of both channels and also Speech Analytics features.
You can also examine the details of the session from the Voicegain Console and listen to the audio. This helps in testing the application before it gets deployed.


If you have questions about building this type of IVRs running on Voicegain platform, please contact us at support@voicegain.ai

Among the various speech-to-text APIs that Voicegain provides is a speech recognition API that uses grammars and supports continuous recognition. This API is ideally suitable for use in warehouse Voice Picking applications. Warehouse Management Systems can embed Voicegain APIs to offer Voice Picking as part of their feature set.
Here are more details of that specific API:
In addition to that Voicegain Speech-to-Text platform provides additional benefits for Voice Picking applications:
Together this allows for your Voice Picking application to continually learn and improve.
Our APIs are available in the Cloud but can also be hosted at the Edge (on-prem) which can increase reliability and reduce the already low latencies.
If you would like to test our API and see how they would fit in your warehouse applications you can start with the fully functional example web app that we have made available on github: platform/examples/command-grammar-web-app at master · voicegain/platform (github.com)
If you have any question please email us at info@voicegain.ai. You can also sign-up for a free account on Voicegain Platform via our Web Console at: https://console.voicegain.ai/signup

This article outlines various options for how developers and builders of real-time Gen AI voice applications in contact center should design and architect access to streaming audio data from IP-based Contact Centers systems. These Contact Center systems can be premise-based contact center platforms like Avaya, Cisco, Genesys or CCaaS platforms like Five9, Genesys Cloud, NICE CXOne and Aircall.
One of the main use cases for Realtime Generative Voice AI in a contact center is Realtime Agent Assist (RTAA) or a generative AI Co-Pilot. The first step for any such realtime application is to stream audio from Contact Center platforms to a streaming Speech-to-Text model and get the speaker separated transcript. This transcript in turn can be integrated with an LLM for real-time sentiment analysis, QA automation agent assist, summarization and other real-time AI use cases in the contact center.
Voicegain's inhouse Kappa model is one such streaming speech-to-text model. The real-time transcript is made available by Voicegain over websockets.
Overall there are 3 main approaches to get access to real-time audio streams
The details of each of those approaches are described below
Most on-premise contact center platforms, like Avaya, Genesys and Cisco do not provide programmatic access to the media streams. Instead they all offer the ability to transfer a call to a SIP destination/URI. This is in turn can be provided by the Voicegain SIP Media Stream B2BUA. In other words, the Voicegain SIP Media Stream B2BUA can accept a call from such a SIP INVITE.
More details of the SIP Media Stream B2BUA can be found here
Most enterprise premise-based Contact Center platforms include a network element called the Session Border Controller (SBC). The SBCs can be thought of as a SIP-aware firewall that is architected "in front" of a premise-based IP Contact Center. SBCs support the forking of audio streams using a protocol called SIPREC and this has been used over the years by active/compliant call recording vendors like NICE and Verint.
With SIPREC, an SBC essentially provides a mirror or fork of the real-time RTP stream from the telephone call. This can be sent to Voicegain's SIPREC Server (currently in beta).
Voicegain has a beta version of a SIPREC interface has been tested with the following platforms:
Voicegain can capture relevant call metadata in addition to obtaining the audio (the metadata capture functionality may differ in capabilities depending on the client platform).
Voicegain platform can be configured to automatically launch transcription and speech-analytics as soon as the new SIPREC session gets established.
SIPREC support is available both in the Cloud and the Edge (OnPrem) deployments of the Voicegain Platform.
SIPREC is an Enterprise feature of the Voicegain platform and is not included in the base package. Please contact support@voicegain.ai or submit a Zendesk ticket for more information about SIPREC and if you would like to use it with your existing Voicegain account.
Some CCaaS platforms, in particular the modern one provide APIs to get programmatic access to the real-time audio stream. In many of them such a capability was added specifically to simplify integration with Cloud Speech-to-Text services.
Examples of such CCaaS platforms are :
Voicegain Platform integrates with the APIs multiple protocols that allow for flexible programmable integration:
All those protocols support uLaw, aLaw, and Linear 16-bit encoding in either 8- or 16kHz sample rate.
If you are building a voice Gen AI application and you would like to discuss getting access to realtime audio data, please contact us at support@voicegain.ai

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices