
Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
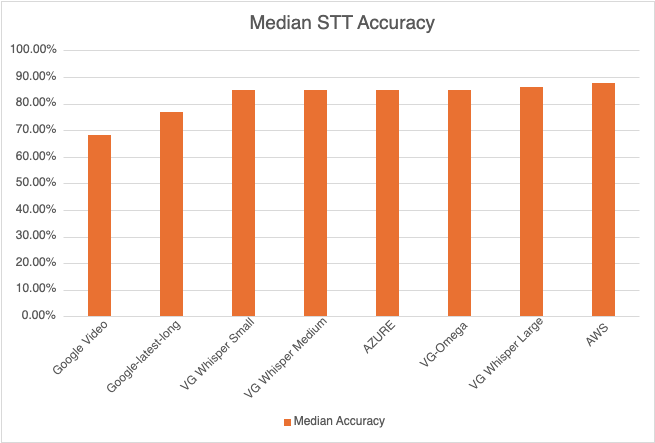
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

This article describes ideas for a business with a speech-enabled IVR to plan its upgrade/transition to a modern generative AI powered conversational Voice Bot on its own timeline and at an affordable cost.
Businesses of all sizes have an IVR system that acts as a front-door for all their customer voice conversations. In terms of functionality, these IVRs systems vary widely; they can range from performing basic call-routing and triaging to automating simple calls - like taking payments, scheduling appointments, or providing account balance etc. While most of them accept touch-tone/DTMF as input, the more advanced ones also accept natural language speech as input and hence referred to as speech-enabled IVRs.
However these IVRs are getting obsolete and there is a growing demand to upgrade to a more conversational experience.
Traditionally Speech IVR applications were deployed on-premise; built on the same platform as the main contact center ACD/Switch. But soon, IVRs were deployed on the Cloud too. The on-premise IVR vendors include Avaya, Genesys and Cisco and cloud-based IVRs include vendors like Five9, RingCentral, Mitel and 8x8.
For speech recognition, the most popular option in the past had been Nuance. Nuance’s ASR technology – which gained popularity in the early2000s - preceded today’s neural-network-based engines. It was pre-Alexa and pre-Siri– and so both the vocabulary (i.e what the customer could actually say in response to a prompt) and the accuracy was limited compared to today’s neural-network-based speech-to-Text. In addition, the protocol for communication between Nuance and the telephony stack was MRCP – a protocol that is not being actively developed for many years now.
Modern Conversational AI Stack for Voice Bots include a modern neural ASR/Speech-to-Text engine and neural Text-to-Speech and a NLU based Bot Framework. It is much more capable than what was available to build directed dialog Speech IVRs in the past.
Today’s neural ASR/STT engines can transcribe not just a few words or phrases, but entire sentences and they also do it very accurately. As consumers get used to such experiences with their voice assistants at home or in their cars, they expect the same when they contact a business over the phone.
There also been significant advances with modern no-code NLU Bot frameworks that are used to build the Bot Logic and conversation flow. These Bot frameworks are also evolving with the advent of generativeAI technologies like ChatGPT.
While the above two paragraphs describe good reasons to upgrade IVRs, there are some key factors that are driving a rather rushed timeline for businesses to plan this IVR migration

Companies with on-premise Contact Centers are increasingly migrating to the Cloud. Even the on-premise contact center vendors too are focused on migrating their install base to the Cloud. So when an enterprise plans to migrate the contact center platform to the cloud, they would need to migrate the IVRs too.
As explained above, modern AI/neural-network-based ASR/STT engines are more accurate and support a conversational experience. Hence ASR/STT vendors are focused on selling these newer offerings. It is not possible for businesses to use these newer ASRs with existing telephony stack. Both the protocol support (Web sockets and gRPC vs MRCP) and the application development method (grammar based vs. large vocabulary transcription with intent capture) are very different.
In the past companies built the application logic for Chatbot and IVR independently; very often different vendors provided the Chatbot and VoiceBot. However, given the powerful and flexible Conversational AI platforms that are available in the market, they want to use the same platform to drive the conversation turns of a Chatbot interaction and a Voice Bot interaction.
As explained above, migrating from the traditional IVR stack to a modern Conversational AI stack entails not just rewriting the application logic but it is also likely to involve moving the infrastructure from on-premise to the cloud. This can be an expensive undertaking.
At Voicegain, we think that can help companies should be able to this at their own timeline.
We have developed an ASR that can support both (a) grammar-based recognition using MRCP and (b) large vocabulary transcription on audio streamed using modern protocols like Websockets. Also our platform can be deployed on-premise or in your VPC. So our platform supports both an existing application without any rewrite while also being capable of supporting a conversation voice bot when it is developed at some point in the future.
As a result, customers can take control of when to migrate/upgrade their IVRs. Most importantly, they would not be forced into invest in an upgrade/migration of their entire IVR application just because an existing ASR vendor would stop supporting an older version of the software.
If you have any questions or you would like to schedule a discussion to understand your IVR upgrade options, contact us on support@voicegain.ai.
To test our MRCP grammar-based ASR or our large vocabulary ASR, please sign up for a free developer account. Instructions are provided here.

Voicegain, the leading Edge Voice AI platform for enterprises and Voice SaaS companies, is thrilled to announce the successful completion of a System and Organizational Control (SOC) 2 Type 1 Audit performed by Sensiba LLP.
Developed by the American Institute of Certified Public Accountants (AICPA), the SOC 2 Information security audit provides a report on the examination of controls relevant to the trust services criteria categories covering security, availability, processing integrity, confidentiality, and privacy. A SOC 2 Type I report describes a service organization's systems, whether the design of specified controls meets the relevant trust services categories. Voicegain’s SOC 2 Type I report did not have any noted exceptions and was therefore issued with a “clean” audit opinion from Sensiba.
"As a Privacy first Voice AI Platform, we take security very seriously here at Voicegain. As a developer using our APIs or as a user of our platform, you shouldn’t have to worry about the controls in place for your sensitive voice data." said Dr Jacek Jarmulak, Co-founder, CTO & CISO Of Voicegain.
"At Voicegain, we have maintained a robust information security program for over a decade now and this has been communicated throughout our organization for quite some time now. Earlier this year, we achieved PCI-DSS compliance for our Developer platform and today's successful completion of the SOC 2 Type 1 Audit marks a significant milestone in our security and compliance journey." continued Dr Jarmulak.
Service Organization Control 2(SOC2) is a set of criteria established by the American Institute of Certified Public Accountants (AICPA) to assess controls relevant to the security, availability, and processing integrity of the systems a service organization uses to process users’ data and the confidentiality and privacy of the information processed by these systems. SOC 2 compliance is important for Voice AI platforms like Voicegain, as it demonstrates that we have implemented controls to safeguard users’ data.
There are two types of SOC 2 compliance:
From a functional standpoint, achieving SOC 2 Type 1 compliance doesn’t change anything. Our APIs and Apps will work exactly as they always have and as expected. However SOC 2 Type 1 compliance means that we have established a set of controls and processes to ensure the security of our users’ data. This compliance demonstrates that we have the necessary measures in place to protect sensitive information from unauthorized access and disclosure.
Our commitment to security doesn’t end with SOC 2 Type 1. We are already working towards achieving SOC 2 Type 2 compliance, which we plan to accomplish in Q1 2024. Thiswill further validate that we maintain the highest levels of security, ensuring that our users can continue to rely on and trust Voicegain.
Voicegain's speech recognition technology has been widely recognized for its innovation and impact across industries. From call centers and customer service applications to transcription of Zoom Meetings in enterprise and healthcare and transcription of classroom lectures, Voicegain's solutions have demonstrated their ability to transform audio data into actionable insights. The attainment of SOC 2 Type 1 compliance further solidifies Voicegain's position as a reliable and responsible provider of cutting-edge speech recognition services.
"We understand that in today's digital landscape, data security is non-negotiable," added Arun Santhebennur, Co-founder & CEO of Voicegain. "By achieving SOC 2 Type 1 compliance, we aim to set an industry standard for ensuring the confidentiality and integrity of the data entrusted to us. Our customers can have full confidence that their sensitive information is protected throughout its lifecycle."
To request a copy of our SOC 2 Type 1 report, please email security.it@voicegain.ai

Today we are really excited to announce the launch of Voicegain Whisper, an optimized version of Open AI's Whisper Speech recognition/ASR model that runs on Voicegain managed cloud infrastructure and accessible using Voicegain APIs. Developers can use the same well-documented robust APIs and infrastructure that processes over 60 Million minutes of audio every month for leading enterprises like Samsung, Aetna and other innovative startups like Level.AI, Onvisource and DataOrb.
The Voicegain Whisper API is a robust and affordable batch Speech-to-Text API for developersa that are looking to integrate conversation transcripts with LLMs like GPT 3.5 and 4 (from Open AI) PaLM2 (from Google), Claude (from Anthropic), LLAMA 2 (Open Source from Meta), and their own private LLMs to power generative AI apps. Open AI open-sourced several versions of the Whisper models released. With today's release Voicegain supports Whisper-medium, Whisper-small and Whisper-base. Voicegain now supports transcription in over multiple languages that are supported by Whisper.
Here is a link to our product page
There are four main reasons for developers to use Voicegain Whisper over other offerings:
While developers can use Voicegain Whisper on our multi-tenant cloud offering, a big differentiator for Voicegain is our support for the Edge. The Voicegain platform has been architected and designed for single-tenant private cloud and datacenter deployment. In addition to the core deep-learning-based Speech-to-text model, our platform includes our REST API services, logging and monitoring systems, auto-scaling and offline task and queue management. Today the same APIs are enabling Voicegain to processes over 60 Million minutes a month. We can bring this practical real-world experience of running AI models at scale to our developer community.
Since the Voicegain platform is deployed on Kubernetes clusters, it is well suited for modern AI SaaS product companies and innovative enterprises that want to integrate with their private LLMs.
At Voicegain, we have optimized Whisper for higher throughput. As a result, we are able to offer access to the Whisper model at a price that is 40% lower than what Open AI offers.
Voicegain also offers critical features for contact centers and meetings. Our APIs support two-channel stereo audio - which is common in contact center recording systems. Word-level timestamps is another important feature that our API offers which is needed to map audio to text. There is another feature that we have for the Voicegain models - enhanced diarization models - which is a required feature for contact center and meeting use-cases - will soon be made available on Whisper.
We also offer premium support and uptime SLAs for our multi-tenant cloud offering. These APIs today process over 60 millions minutes of audio every month for our enterprise and startup customers.
OpenAI Whisper is an open-source automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. The architecture of the model is based on encoder-decoder transformers system and has shown significant performance improvement compared to previous models because it has been trained on various speech processing tasks, including multilingual speech recognition, speech translation, spoken language identification, and voice activity detection.

Learn more about Voicegain Whisper by clicking here. Any developer - whether a one person startup or a large enterprise - can access Voicegain Whisper model by signing up for a free developer account. We offer 15,000 mins of free credits when you sign up today.
There are two ways to test Voicegain Whisper. They are outlined here. If you would like more information or if you have any questions, please drop us an email support@voicegain.ai

We are super excited to announce the release of two new features with our Voicegain Transcribe app.
(i) Summarization powered by LLMs.
(ii) Single Sign On (Currently available for Voicegain Edge/On-Prem customers only)
Summarization of a transcript is extremely valuable for various types of audio content. Whether a user is transcribing a business meeting, a classroom lecture, a podcast or a web event, reviewing just the summary of the transcript is a big time-saver compared to having to read the entire transcript. With this release, every transcript generated by Voicegain Transcribe will be summarized accurately using powerful state-of-the-art LLMs.
In addition to the summary of the transcript, Voicegain also supports extraction of key items like Actions, Issues, Risks, and Dependencies.
For users of Voicegain Transcribe Cloud, the summarization is powered by ChatGPT (GPT 3.5 Turbo APIs). Essentially we submit the meeting transcript to ChatGPT and we ask it to summarize the meeting. We display and store the returned summary in Voicegain Transcribe.
For users of Voicegain Transcribe Edge/On-Prem, we offer an open-source LLM model that has been fine-tuned on meeting data. This fine-tuned LLM model gets deployed along with the entire Voicegain platform behind the customer's firewall (whether in a private cloud or datacenter).
With this new release, Voicegain Transcribe also supports the SSO feature using the OIDC protocol. Most popular Identity Management software solutions - like Okta, Ping Identity, Microsoft, Oracle, RSA etc support the OIDC protocol.
This feature is currently available only to Voicegain Edge/On-Prem customers and it will be made available very soon to Voicegain Cloud customers too.
Voicegain Transcribe is a privacy-first Meeting AI platform that can be deployed "fully behind" the firewall of a company/business. It is also available for access as a cloud service.
By signing up today, you will be signed up on our forever Free Plan - which makes you eligible for 120 mins of Meeting Transcription free every month . Once you are satisfied with our accuracy and our user experience, you can easily upgrade to Paid Plans or contact us for On-Premise/Virtual Private Cloud options.
If you have any questions, please email us at support@voicegain.ai

LLMs like ChatGPT and Bard are taking the world by storm! An LLM like ChatGPT is really good at both understanding language and acquiring knowledge of this content. The outcome of this is almost eerie and scary. Because once these LLMs acquire knowledge, they are able to answer very accurately questions that in the past seemed to require human judgement.
One big use-case for LLMs is in the analysis of business meetings - both internal (between employees) and external (e.g conversations with customers, vendors, etc).

In the past few years, companies have been primarily using multi-tenant Revenue/Sales Intelligence and Meeting AI SaaS offerings to transcribe business conversations and extract insights. With such multi-tenant offerings, transcription and natural language processing takes place on the Vendor cloud. Once the transcript is generated, NLU models offered by the Meeting AI vendor is used to extract insights. E.g, Revenue intelligence products like Gong extract questions and sales blockers in sales conversations. Most meeting AI assistants extract summaries and action items.
Essentially these NLU models - and many of these predate the LLMs - were able to summarize, extract topics, keywords and phrases. Enterprises did not mind using the cloud infrastructure of the vendor to store the transcripts as what this NLU could do seemed pretty harmless.
However the LLMs take this to a whole different level. Our team used Open AI Embeddings API to generate embeddings of our daily meeting transcripts that were conducted over a one-month period. We stored these embeddings in an open-source Vector database (our knowledge-base). During testing, for each user question, we generated embedding of the question and queried the vector database (i.e knowledge-base) to get related/similar embeddings.
Then we provided these related documents as context and the user question as a prompt to GPT 3.5 API so that it could generate the answer. We got really really good results.
We were able to get answers to the following questions
1. Provide a summary of the contract with <Largest Customer Name>.
2. What is the progress on <Key Initiative>?
3. Did the Company hire new employees?
4. Did the Company discuss any trade secrets?
5. What is the team's opinion on Mongodb Atlas vs Google Firestore?
6. What new products is the Company planning to develop?
7. Which Cloud provider is the Company using?
8. What is the progress on a key initiative?
9. Are employees happy working in the company?
10. Is the team fighting fires?
ChatGPT's responses to the above questions was amazingly and eerily accurate. For Question 4, it did indicate that it did not want to answer the question. And when it do not have adequate information (e.g. Question 9), it did indicate that in its response.
At Voicegain, we had always been a big proponents of why Voice AI needs to remain on the Edge. We had written about it in the past.
Meeting transcripts in any business is a veritable gold mine of information. Now with the power of LLMs, they can now be queried very easily to provide amazing insights. But if these transcripts are stored in another Vendor's cloud, it has the potential to expose very proprietary and confidential information of any business to 3rd parties.
Hence for businesses it is extremely critical that such transcripts are stored only in private infrastructure (behind the firewall). It is really important for Enterprise IT to make sure this happens in order to safeguard proprietary and confidential information.
If you are looking for such a solution, we can help. At Voicegain, we offer Voicegain Transcribe, an enterprise-ready solution for Meeting AI. With Voicegain Transcribe, the entire solution can deployed either in a datacenter (on bare-metal) or in a private cloud. You can read more about it here.

On March 1st 2023, Open AI announced that developers could access the Open AI Whisper Speech-to-Text model via easy-to-use REST APIs. OpenAI also released APIs to GPT3.5, the LLM behind the buzzy ChatGPT product. General availability of the next version of LLM - GPT 4 is expected in July 2023.
Since Open AI Whisper's initial release in October 2022, it has been a big draw for developers. A highly accurate open-source ASR is extremely compelling. OpenAI's Whisper has been trained on 680,000 hours of audio data which is much more than what most models are trained on. Here is a link to their github.
However the developer community looking to leverage Whisper faces three major limitations:
1. Infrastructure Costs: Running Whisper - especially the large and medium models - requires expensive memory-intensive GPU based compute options (see below).
2. In-house AI expertise: To use Open AI's Whisper model, a company has to invest in building an in-house ML engineering team that is able to operate, optimize and support Whisper in a production environment. While Whisper provides core features like Speech-to-Text, language identification, punctuation and formatting, there are still some missing AI features like speaker diarization and PII redaction that would need to be developed. In addition, companies would need to put in place a real-time NOC for ongoing support. Even a small scale 2-3 person developer team could be expensive to hire and maintain - unless the call volumes justify such an investment. This in-house team also needs to take full responsibility for the Cloud infrastructure related tasks like auto-scaling and log monitoring to ensure uptime.
3. Lack of support for real-time: Whisper is a batch speech-to-text model. For developers requiring streaming Speech-to-Text models, they need to evaluate other ASR/STT options.
By now taking over the responsibility of hosting this model and making it accessible via easy-to-use APIs, both Open AI and Voicegain addresses the first two limitations.
Aug 2023 Update: On Aug 5th 2023, Voicegain announced the release Voicegain Whisper, an optimized version of Open AI's Whisper using Voicegain APIs. Here is a link to the announcement. In addition to Voicegain Whisper, Voicegain also offer realtime/streaming Speech-to-Text and other features like two-channel/stereo support (required for call centers), speaker diarization and PII redaction. All of this is offered in Voicegain's PCI and SOC-2 compliant infrastructure.
This article highlights some of the key strengths and limitations of using Whisper - whether using Open AI's APIs, Voicegain APIs or hosting it on your own.
In our benchmark tests, OpenAI's Whisper models demonstrated high accuracy for a widely diverse range of audio datasets. Our ML engineers concluded that the Whisper models perform well on audio datasets ranging from meetings, podcasts, classroom lectures, YouTube videos and call center audio. We benchmarked Whisper-base, Whisper-small and Whisper-medium against some of the best ASR/Speech-to-Text engines in the market.
The median Word Error Rate (WER) for Whisper-medium was 11.46% for meeting audio and 17.7% for call center audio. This was indeed lower than the WERs of STT offerings of other large players like Microsoft Azure and Google. We did find that AWS Transcribe had a WER that is competitive with Whisper.
Here is an interesting observation - it is possible to exceed Whisper's recognition accuracy, however it would take building custom models. Custom models are models that are trained on our client's specific audio data. In fact for call center audio, our ML Engineers were able to demonstrate that our call-center specific Speech-to-text models were either equal to or even better than some of the Whisper models. This makes intuitive sense because call center audio is not readily available on the internet for Open AI to get access to.
Please contact us via email (support@voicegain.ai) if you would like to review and validate/test these accuracy benchmarks.
Whisper's pricing at $0.006/min ($0.36/hour) is much lower than the Speech-to-Text offerings of some of the other larger cloud players. This translates to a 75% discount to Google Speech-to-Text and AWS Transcribe (based on pricing as of the date of this post).
Aug 2023 Update: At the launch of Voicegain Whisper, Voicegain announced a list price at $0.0037/min ($0.225/hour). This price is 37.5% lower than Open AI's price and has been accomplished since we optimized the throughput of Whisper. To test it out, please sign up for a free developer account. Instructions are provided here.
What was also significant was Open AI announced the release of ChatGPT APIs with the release of Whisper APIs. Developers can combine the power of Whisper Speech-to-Text models with the GPT 3.5 and GPT 4.0 LLM (the underlying model that ChatGPT uses) to power very interesting conversational AI apps. However here is an important consideration - Using Whisper API with LLMs like ChatGPT works as long as the app only uses batch/pre-recorded audio (e.g analyzing recording of call center conversations for QA or Compliance or transcribe and mine Zoom meetings to recollect context). For developers looking to build Voice Bots or Speech IVRs, they would need a good real-time Speech-to-Text model.
As stated above, Open AI's Whisper does not support apps that require real-time/streaming transcription - this could be relevant to a wide variety of AI apps that target call center, education, legal and meetings use-case. In case you are looking for a streaming Speech-to-Text API provider, please feel free to contact us with the email address provided below
The throughput of Whisper models - both for the medium and large models - is relatively low. At Voicegain, our ML engineers have tested the throughput of Whisper models on several popular NVIDIA GPU-based compute instances available in public clouds (AWS, GCP, Microsoft Azure and Oracle Cloud). We also have real-life experience because we process over 10 million hours of audio annually. As a result, we have a strong understanding of what it takes to run a model like OpenAI's Whisper in a production environment.
We have found out that the infrastructure cost of running Whisper-medium in a cloud environment is in the range of $0.07 - $0.10/hour. You can contact us via email to get the in-depth assumptions and backup behind our cost model. An important factor to note is that in a single-tenant production environment the compute infrastructure cannot be run at a very high utilization. The peak throughput required to support real-life traffic can be several times (2-3x) the average throughput. Net-net, we determined that while developers would not have to pay for software licensing, the cloud infrastructure costs would still remain substantial.
In addition to this infrastructure cost the larger expense of running Whisper on the Edge (On-Premise + Private Cloud) is that it would require a dedicated back-end Engineering & Devops team that can chop the audio recording into segments that can be submitted to Whisper and perform the queue management. This team would need to also oversee all info-sec and compliance needs (e.g. running vulnerability scans, intrusion detection etc).
As of the publication of this post, Whisper does not have a multi-channel audio API. So if your application involves audio with multiple speakers, then Whisper's effective price-per-min = Number of channels * 0.006. For both meetings and call center use-cases, this pricing can become prohibitive.
This release of Whisper is missing some key features that developers would need. The three important features we noticed are Diarization (speaker separation), Time-stamps and PII Redaction.
Voicegain is working on releasing a Voicegain-Whisper Model over its APIs. With this developers can get benefits of Voicegain PCI/SOC-2 compliant infrastructure and advanced features like diarization, PII redaction, PCI compliance and time-stamps. To join the waitlist, please email us at sales@voicegain.ai
At Voicegain, we build deep-learning-based Speech-to-Text/ASR models that match or exceed the accuracy of STT models from the large players. For over 4 years now, startup and enterprise customers have used our APIs to build and launch successful products that process over 600 million minutes annually. We focus on developers that need high accuracy (achieved by training custom acoustic models) and deployment in private infrastructure at an affordable price. We provide an accuracy SLA where we guarantee that a custom model that is trained on your data will be as accurate if not more than most popular options including Open AI's Whisper.
We also have models that are trained specifically on call center audio. While Whisper is a worthy competitor (of course a much larger company with 100x our resources), as developers we welcome the innovation that Open AI is unleashing in this market. By adding ChatGPT APIs to our Speech-to-Text , we are planning to broaden our API offerings to developer community.
To sign up for a developer account on Voicegain with free credits, click here.

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices