
Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
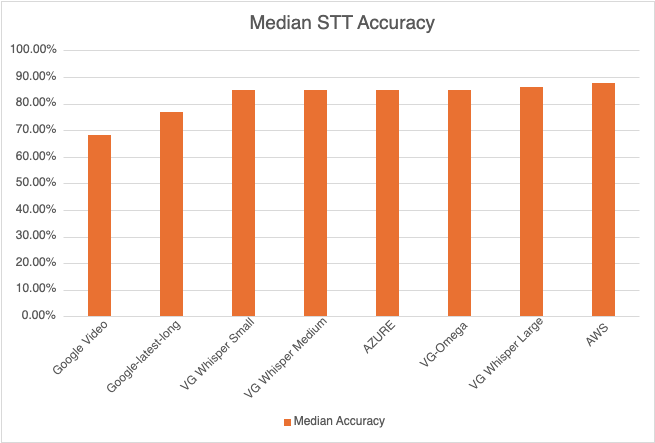
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

Businesses of all sizes are looking to develop Voicebots to automate customer service calls or voice based sales interactions. These bots may be voice versions of existing Chatbots, or exclusively voice based bots. While Chatbots automate routine transactions over the web, many users like the ability to use voice (app or phone) when it is convenient.
A voice bot dialog consists of multiple interactions where a single interaction typically involves 3 steps:
For the first step, developers use a Speech-to-Text platform to transcribe the spoken utterance into text. ASR or Automatic Speech Recognition is another term that is used to describe the same type of software.
When it comes to extracting intent from the customer utterance, they typically use an NLU engine. This is understandable because developers would like to re-use the dialog flow or conversation turns programmed in their Chatbot App for their Voicebot.
A second option is to use Speech Grammars which match the spoken utterance and assign meaning (intent) to it. This option is not in vogue these days but Speech Grammars have been successfully used in telephony IVR systems that supported speech interaction using ASR.
This article explores both approaches to building Voicebots.
Most developers today use the NLU approach as a default option for Steps 2 and 3. Popular NLU engines include Google Dialog Flow, Microsoft LUIS, Amazon Lex and also increasingly an open source framework like RASA.
An NLU Engine helps developers configure different intents that match training phrases, specify input and output contexts that are associated with these intents, and define actions that drive the conversation turns. This method of development is very powerful and expressive. It allows you to build bots that are truly conversational. If you use NLU to build a Chatbot you can generally reuse its application logic for a Voicebot.
But it has a significant drawback. You need to hire highly skilled natural language developers. Designing new intents, handling input and output contexts, entities etc is not easy. Since you require skilled developers, the development of bots using NLU is expensive. It is not just expensive to build but it is costly to maintain too. For example, if you want to add new skills to the bot that are beyond its initial set of capabilities, modifying the contexts is not an easy process.
Net-net the NLU approach is a really good fit if (a) you want to develop a sophisticated bot that can support a truly conversational experience (b) you are able to hire and engage skilled NLP developers and (c) you have adequate budgets to develop such bots.
One approach that was used in the past and seems to have been forgotten these days is the use of Speech Grammars. Grammars were used extensively to build traditional telephony based speech IVRs for over 20 years now, but most NLP and web developers are not aware of them.
A Speech Grammar provides either a list of all utterances that can be recognized, or, more commonly, a set of rules that can generate the utterances that can be recognized. Such grammar combines two functions:
The second function is achieved by attaching tags to the rules in the grammars. Tag formats exist that support complex expressions to be evaluated for grammars that have many nested rules. These tags allow the developer to essentially code intent extraction right into the grammar.
Also Step 3 - which is the dialog/conversation flow management - can be implemented in any backend programming language - Java, Python or Node.js. Developers of voice bots that are on a budget and are looking to building a simple bot with just a few intents should strongly consider grammars as an alternative approach to NLU.
Voicegain is one of the few Speech-to-Text or ASR engines that supports both approaches.
Developers can easily integrate Voicegain's large vocabulary speech-to-text (Transcribe API) with any popular NLU engine. One advantage that we have here is the ability to output multiple hypotheses - when using the word-tree output mode. This allows multiple NLU intent matches to be done of the different speech hypotheses with the goal of determining if the there is an NLU consensus in spite of differing speech-to-text output. This approach can deliver higher accuracy.
We also provide our Recognize API and RTC Callback APIs ; both of these support speech grammars. Developers may code the application flow/dialog of the voicebot in any backend programming language - Java, Python, Node.Js. We have extensive support for telephony protocols like SIP/RTP and we support WebRTC.
Most other STT engines - including Microsoft, Amazon and Google - do not support grammars. This may have something to do with the fact that they are also trying to promote their NLU engines for chatbot applications.
If you are building a Voicebot and you'd like to have a discussion on which approach suits you, do not hesitate to get in touch with us. You can email us at info@voicegain.ai.

Many applications of speech-to-text (STT) or speech recognition (ASR) require that the conversion from audio to text happen in realtime. These applications could be voice bots, live captioning of videos, events or talks, transcription of meetings, real time speech analytics of sales calls or agent assistance in a contact center.
An important question for developers looking to integrate real time STT into their apps is the choice of the protocol and/or mechanism to stream real time audio to the STT platform. While some STT vendors offer just one method; at Voicegain we offer multiple choices that developers could select from. In this post, we explore in detail all these methods so that a developer could choose the right one for their specific use case.
Some of the factors that may guide the specific choice are:
At Voicegain we currently offer seven different methods/protocols to support streaming to our STT platform. The first three are TCP based methods and the last four methods are UDP based.
Using WebSockets is a simple and popular option to stream audio to Voicegain for speech recognition. WebSockets have been around for a while and most web programming languages have libraries that support it. This option may be the easiest way to get started. Voicegain API is using binary WebSockets, and we have some simple examples to get you started.
Voicegain also supports streaming over HTTP 1.1 using chunked transfer encoding. This allows you to send raw audio data with unknown size, which is generally the case for streaming audio. Voicegain supports both pull and push scenarios - we can fetch the audio from a URL that you provide or the application can submit the audio to a URL that we provide. To use this method, your programming language should have libraries that support chunked transfer encoding over HTTP, some of the older or simpler HTTP libraries do not support it.
gRPC builds on top of HTTP/2 protocol which was designed to support long-running bi-directional connections. Moreover, gRPC uses Protocol buffers which are a more efficient data serialization format compared to JSON that is commonly used in RESTful HTTP APIs. Both these aspects of gRPC allow audio data to be efficiently sent over the same connection that is also used for sending commands and receiving results.
With gRPC, client side libraries can easily be generated for multiple languages, like Java, C#, C++, Go, Python, Node Js, etc. The generated client code contains stubs for use by gRPC clients to call the methods defined by the service.
Using gRPC, clients can invoke the Voicegain STT APIs like a local object whose methods expose the APIs. This method is a fast, efficient, and low-latency way to stream audio to Voicegain and receive recognition responses. The responses are sent over the same connection back from the server to client - this removes the need for polling or callbacks to get the results when using HTTP.
gRPC is great when used from the back-end code or from Android. It is not a plug and play solution when used from Web Browsers but requires some extra steps.
The first three methods described above are TCP based methods. They work great for audio streaming as long as the connection has no or minimal packet loss. Packet loss causes significant delays and jitter in the TCP connections. This may be fine if audio does not have to be processed truly real-time and can be buffered.
If real-time behavior is important and the network is known to be unreliable, the UDP protocol is a better alternative to TCP for audio streaming. With UDP, packet loss will manifest itself as audio dropouts, but that may be preferable to excessive pauses and jitter in case of TCP.
RTP is a standard protocol for audio streaming over UDP. However, RTP itself is is generally not sufficient and is normally used with accompanying RTP Control Protocol (RTCP). Voicegain has implemented its own variation of RTCP that can be used to control RTP audio streams sent to the recognizer.
Currently, the only way to to stream audio using RTP to Voicegain platform is to use our proprietary Audio Sender Java library. We also provide Audio Sender Daemon that is capable of reading data directly from audio devices and streaming it to Voicegain for real time transcription.
If you are looking to invoke Speech-to-text in a contact center, Voicegain offers Telephony Bot APIs. You can read more about them here. Essentially the Voicegain platform can act as a SIP endpoint and can be invited into a SIP session. We can do two things 1) As part of an IVR or Bot, play prompts and gather caller input 2) As part of a real-time agent assist, we can listen & transcribe the agent-caller interaction.
To elaborate on (1), with these APIs you can invite the Voicegain platform into a SIP session which provides Voicegain Speech-to-Text engine access to the audio. Once the audio stream gets established, you can issue commands to recognize call utterances and receive the recognition response using our web callbacks. You can write the logic of your application using any programming language or an NLU Engine of your choice - all that is needed is being able to handle HTTP requests and send responses.
Voicegain platform in this scenario essentially acts as a 'mouth' and an 'ear' to the entire conversation which happens over SIP/RTP. The application can issue JSON commands over HTTP that play prompts and convert caller speech into text through the entire duration of the call over a single session. You can also record the entire conversation if the call is transferred to a live agent and transcribe into text.
Contact center platform vendors like Cisco, Genesys, Avaya and FreeSWITCH based CCaaS platforms usually support MRCP to connect to Speech Recognition engines. Voicegain supports access over MRCP to both large vocabulary and grammar based speech recognition. We recommend MRCP only for Edge, Private Cloud or On-premise deployments
In Contact Centers, for real-time transcription of the agent caller interaction, Voicegain supports SIPREC. Further information is provided here.
1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click hereto sign up for a developer account and receive $50 in free credits
3. If you want to take Voicegain as your own AI Transcription Assistant to meetings, click here.

Update Dec 2020: We have renamed RTC Callback APIs to Telephony Bot APIs to better reflect how developers can use these APIs - which is build Voice Bots, IVRs.
If you have wanted to voice enable your Chatbot or build your own Telephony based Voice Bot or a Speech-enabled IVR, Voicegain has built an API that is really cool - Release 1.12.0 of Voicegain Speech-to-Text Platform now includes Telephony Bot APIs (formerly called RTC Callback APIs in the past).
Voicegain Telephony Bot APIs enables any NLU/Bot Framework to easily integrate with PSTN/telephony infrastructure using either (a) SIP INVITE of Voicegain platform from a CPaaS platform of your choice or (b) purchasing a phone number directly from Voicegain portal and pointing it to your Bot. You can then use these callback style APIs to (i) play prompts (ii) recognize speech utterances or DTMF digits (iii) allow for barge-in and several other exciting features. We offer sample code that will help you easily integrate a Bot Framework of your choice to our Telephony Bot APIs.
If you do not have a Bot Framework, thats okay too. You can write the logic in any backend programming language (Python, Java or Node.JS) that can serialize responses in a JSON format and interact with our Callback style APIs. Voicegain also offers a declarative YAML format to define the call flow and you can host this YAML file logic and interact with these APIs. Developers can also code and deploy the application logic in a server-less computing environment like Amazon Lambda.
Many enterprises - in banking, financial services , health care, telecom and retail - are stuck with legacy telephony based IVRs that are approaching obsolescence.
Voicegain's Telephony Bot APIs provide a great future-proof upgrade path for such enterprises. Since these APIs are based on web callbacks, they can interact with any backend programming language. So any backend web developer can design, build and maintain such apps.
With Telephony Bot APIs, integration becomes much simpler for developers.
1) You can SIP INVITE the Voicegain Speech-to-Text/ASR platform to a SIP/RTP session for as long as is needed. We support SIP integration with CPaaS platforms like Twilio, Signalwire and Telnyx. We also support CCaaS platforms like Genesys, Cisco and Avaya.
2) We also support direct phone number ordering and SIP Trunks from the Voicegain Web Console. More integrations will be added soon.
Telephony Bot APIs are based on web callbacks where the actual program/ implementation is on the Client side and the Voicegain Telephony Bot APIs define the Requests and Responses. The meaning of Requests and Responses is reversed w.r.t what you would see in a normal Web API:
Below is an example of a simple phone call interaction which is controlled by Telephony Bot API. The sequence diagram shows 4 callbacks during a toy survey call:

Telephony Bot API supports 4 types of actions:
Each call can be recorded (two channel recording) and then transcribed. The recording and the transcript can be accessed from the portal as well as via the API.
Features coming soon:

As of August 5th, 2020, programming in Python against Voicegain Speech-to-Text (STT) API got even easier with the release of official voicegain-speech package to Python Package Index (PyPI) repository.
The SDK package is available at: https://pypi.org/project/voicegain-speech/
The SDK source code is available at: https://github.com/voicegain/python-sdk
This package wraps Voicegain Speech-to-Text Web API. A preview of the API spec can be found at: https://www.voicegain.ai/api
Full API spec documentation is available at: https://console.voicegain.ai/api-documentation
The core APIs are for Speech-to-Text, either transcription or recognition (further described below).Other available APIs include:
/asr/transcribeThe Transcribe API allows you to submit audio and receive the transcribed text word-for-word from the STT engine. This API uses our Large Vocabulary language model and supports long form audio in async mode.
The API can, e.g., be used to transcribe audio data - whether it is podcasts, voicemails, call recordings, etc. In real-time streaming mode it can, e.g., be used for building voice-bots (your the application will have to provide NLU capabilities to determine intent from the transcribed text).
The result of transcription can be returned in four formats:
/asr/recognizeThis API should be used if you want to constrain STT recognition results to the speech-grammar that is submitted along with the audio (grammars are used in place of the large vocabulary language model).
While having to provide grammars is an extra step (compared to Transcribe API), they can simplify the development of applications since the semantic meaning can be extracted along with the text.
Another advantage of using grammars is that they can ignore words in the utterance that are outside of grammar - still delivering recognition although with lower confidence.
Voicegain supports grammars in the JSGF and GRXML formats – both grammar standards used by enterprises in IVRs since early 2000s.The recognize API only supports short form audio - no more than 60 seconds.

We have recently added support for CORS (Cross Origin Resource Sharing) in our APIs. This was in response to our customers asking for it in order to enable them building Speech-to-Text web applications with minimal effort. By making web API requests to Voicegain Speech API directly from their web clients the application can be simpler and more efficient.
Examples of simple applications that our customers are implementing this way are: microphone input capture and transcription (e.g. to capture and transcribe meeting notes), or offline-audio file transcription.
Users have full control, via security settings, over which Origins should be allowed to make the CORS requests.

There is no doubt that there is a lot of value in the datasets that are used to train AI models. That is one of the reasons why Google offers their Speech-to-Text service at two price points, one with 'data logging' and and one without, see table below.

However at Voicegain, our speech-to-text platform does not capture or use any customer data (while still being able to offer low ASR pricing).
Moreover, Voicegain platform enables our customers to use their data to train their own dedicated & custom Acoustic Models. As result, our customers benefit in two ways:
By retaining ownership of the data and the custom acoustic models, our customers benefit from higher ASR accuracy in general, and higher accuracy than their potential competitors in particular.

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices