
Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
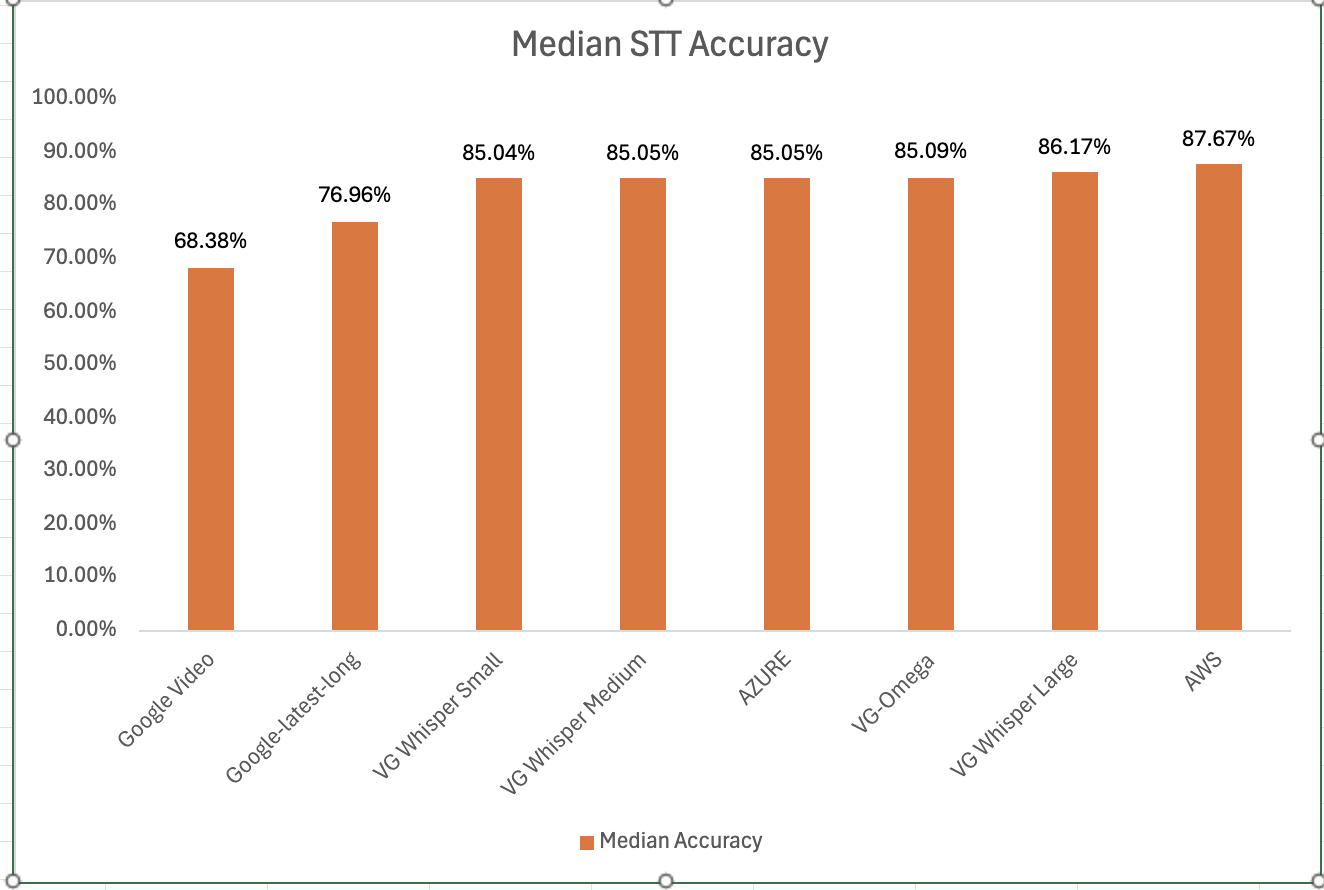
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

This article outlines various options for how developers and builders of real-time Gen AI voice applications in contact center should design and architect access to streaming audio data from IP-based Contact Centers systems. These Contact Center systems can be premise-based contact center platforms like Avaya, Cisco, Genesys or CCaaS platforms like Five9, Genesys Cloud, NICE CXOne and Aircall.
One of the main use cases for Realtime Generative Voice AI in a contact center is Realtime Agent Assist (RTAA) or a generative AI Co-Pilot. The first step for any such realtime application is to stream audio from Contact Center platforms to a streaming Speech-to-Text model and get the speaker separated transcript. This transcript in turn can be integrated with an LLM for real-time sentiment analysis, QA automation agent assist, summarization and other real-time AI use cases in the contact center.
Voicegain's inhouse Kappa model is one such streaming speech-to-text model. The real-time transcript is made available by Voicegain over websockets.
Overall there are 3 main approaches to get access to real-time audio streams
The details of each of those approaches are described below
Most on-premise contact center platforms, like Avaya, Genesys and Cisco do not provide programmatic access to the media streams. Instead they all offer the ability to transfer a call to a SIP destination/URI. This is in turn can be provided by the Voicegain SIP Media Stream B2BUA. In other words, the Voicegain SIP Media Stream B2BUA can accept a call from such a SIP INVITE.
More details of the SIP Media Stream B2BUA can be found here
Most enterprise premise-based Contact Center platforms include a network element called the Session Border Controller (SBC). The SBCs can be thought of as a SIP-aware firewall that is architected "in front" of a premise-based IP Contact Center. SBCs support the forking of audio streams using a protocol called SIPREC and this has been used over the years by active/compliant call recording vendors like NICE and Verint.
With SIPREC, an SBC essentially provides a mirror or fork of the real-time RTP stream from the telephone call. This can be sent to Voicegain's SIPREC Server (currently in beta).
Voicegain has a beta version of a SIPREC interface has been tested with the following platforms:
Voicegain can capture relevant call metadata in addition to obtaining the audio (the metadata capture functionality may differ in capabilities depending on the client platform).
Voicegain platform can be configured to automatically launch transcription and speech-analytics as soon as the new SIPREC session gets established.
SIPREC support is available both in the Cloud and the Edge (OnPrem) deployments of the Voicegain Platform.
SIPREC is an Enterprise feature of the Voicegain platform and is not included in the base package. Please contact support@voicegain.ai or submit a Zendesk ticket for more information about SIPREC and if you would like to use it with your existing Voicegain account.
Some CCaaS platforms, in particular the modern one provide APIs to get programmatic access to the real-time audio stream. In many of them such a capability was added specifically to simplify integration with Cloud Speech-to-Text services.
Examples of such CCaaS platforms are :
Voicegain Platform integrates with the APIs multiple protocols that allow for flexible programmable integration:
All those protocols support uLaw, aLaw, and Linear 16-bit encoding in either 8- or 16kHz sample rate.
If you are building a voice Gen AI application and you would like to discuss getting access to realtime audio data, please contact us at support@voicegain.ai

Our latest release (1.24.0) expands Voicegain Speech Analytics and Transcription API with ability to redact sensitive data both in transcript and in audio. This allows our customers to be compliant with standards like HIPAA, GDPR, CCPA, PCI or PIPEDA.
Any of the following types of Named Entities can be redacted in transcript text and/or the audio file.
In the audio they are replaced with silence and in the transcript they are replaced with a string specified when making the API request.
This feature is supported both in Cloud and on the Edge (on-prem).
Two typical use cases are:

Last week we announced that Spanish Speech-to-Text capability would be available from Voicegain in March. We are pleased to announce today that we have been able to complete training of the Spanish Neural Network Model earlier than expected and the Spanish Speech-to-Text has been released last Saturday (2/20) as part of our Release 1.24.0.
We have been able to complete work on the Spanish model from start to finish in exactly 3 weeks - we started working on it February 3rd. Such fast progress was possible because of our extensive experience with customization of Neural Network Models for speech recognition and the fact that we have developed advanced tools and proven techniques that make speech-to-text model development and training fast.
The recognition accuracy of the model depends on the type of speech audio. For most benchmark files our Spanish model accuracy is just a few % behind that of Google or Amazon recognizers. The advantage of our recognizer is the significantly lower price plus ability to train customized acoustic models. Custom models can have accuracy higher than that of Amazon or Google. We encourage you to use our Web Console and/or API to test the real-life performance on your own data. BTW, we are focusing this speech-to-text model on Latin American Spanish.
Of course, Voicegain platform offers other advantages too like support for Edge (on-prem) deployments and extensive API with many options for out-of-the-box integration into e.g. telephony environments.
Currently, Speech-to-Text API is fully functional with the Spanish Model. Some of the Speech Analytics API functions are not yet available for Spanish, e.g., Named Entity Recognition or Sentiment/Mood detection.
Initially the Spanish Model is available only in the version that supports off-line transcription. Real-time version of the Model will be available in the near future,
To tell the API that you want to use the Spanish Acoustic Model all you need to do is choose it in the Context settings. Spanish models have 'es' in the name, e.g. VoiceGain-ol-es:1

Voicegain speech-to-text platform has supported RTP streaming from the very beginning. One of our first applications, several years ago, was live transcription with ffmpeg utility used to capture audio from a device and to stream it to the Voicegain platform using RTP. Over time we added more robust protocols and RTP was rarely used. However, recently in one of our deployments we came across a use case where RTP streaming allowed our customer to do integration in a very straightforward way within a call-center telephony stack.
Voicegain platform does support more advanced streaming protocols for call-center use like SIPREC or SIP/RTP (SIP Invite). However, in this particular use we were able to stream from Cisco CUBE directly to Voicegain using plain RTP. Upon receiving an incoming call a script is triggered which uses HTTP to establish new Voicegain transcription session. In the session response, ip:port parameters for the RTP receiver specific to the session are returned and these are passed to the CUBE to establish a direct RTP connection.
RTP used like this provides no authentication and security which would make it generally unsuitable for use over Internet. However, in this particular use case our customer benefits from the fact that the entire Voicegain stack can be deployed on-prem. Because of being on the same isolated network as the CUBE there are no issues with security and/or packet loss.
You can visit out github to see a python code example which shows how to establish the speech-to-text session, how to point the RTP sender to the receiver endpoint, and how to receive real-time transcription result via a websocket.
The command to establish the session is as simple as this:
Audio section defines the RTP streaming part, and the websocket section defines how the results will be sent back over a websocket.
The response looks like this:
In the github example the stream.ip and stream.port are passed to ffmpeg that is used as the RTP streaming client. The example further illustrates how to process the messages with incremental transcription results sent real-time over the websocket.

Voicegain has released its Speech Analytics (SA) API that supports variety of analytics tasks performed on the audio or the transcript of that audio. The features supported by Voicegain SA API were chosen to support our target main use case which is processing Call Center calls.
The current release supports offline Speech Analytics. The data that can be obtained through Speech Analytics API is listed below.
Note, here we do not include things that can be obtained also from our Transcribe API, like: transcript, decibel values, audiozones, etc. These, however, will be accessible from the Speech Analytics API response.
Per channel analytics:
Global analytics:
Real-time Speech Analytics will be available in the near future. Soon we also plan to release Score Card support for Speech Analytics.
Per channel analytics coming soon:
Additionally, we will soon support PII redaction of any named entity from either transcript or audio.
Speech Analytics API supports the following types of audio input:
You can see the API specification here.

In this blog post we present a unique feature of the Voicegain speech-to-text platform that efficiently combines the use of grammars with the use of large vocabulary models to provide developers with the ability to achieve high recognition accuracy in a very efficient and convenient way.
Speech recognition (ASR) systems generally can be divided into two types:
This type of recognizer is generally used for transcription where the vocabulary is very broad and the length of the speech audio is unlimited (except for practical e.g. resource related limit). Typical components and processing steps of such a system are illustrated below:

The working of such a system is as follows: (s) The audio signal is processed into features. (b) The features are fed into an acoustic model processor. The processor converts data from the acoustic realm to text/linguistic or some other intermediate (e.g. audio embeddings) realm. The output values may be phonemes, letters, word pieces, audio embeddings, etc., presented as vectors of probabilities. (c) These vectors are then passed to search/optimization component. Search uses the language model to decide which hypotheses formed from the output of the previous stage are most likely to be the correct textual interpretation of the input speech audio.
The Language Models used may take variety of forms. Two of the many possible manifestations are: (a) ARPA language models, which are n-gram based, and (b) Neural Network language models where a neural network (e.g., RNN) is trained to represent a language model. Some of the Language models can also incorporate a decoder part, if the acoustic model output is encoded (e.g. if it is represented by acoustic embedding).
Because the vocabulary of this type of recognizers is large, they are prone to misrecognitions. This is particularly the case for short utterances that do not provide much context for the language model to sufficiently constrain the hypotheses. An example would be misrecognizing “card” as “car” if that is the only word that is said and a speaker has a specific accent.
Cloud speech-to-text offerings from the Big Cloud providers - Google, Amazon, and Microsoft are all examples of Large Vocabulary ASRs.
In such a system, the Voice Bot/IVR developer uses a context free grammar to define a set of possible utterances that can be recognized. The grammars are typically defined using the SRGS (Speech Recognition Grammar Specification) standard - either ABNF or GRXML grammar. Other types of grammars used are JSGF (JSpeech Grammar Format) and GSL (which is Nuance Grammar Specification Language).
Components and processing steps of a typical speech recognition system that uses such grammars are illustrated below:

In this system the evaluation of the output from acoustic model processing is done by a search/optimizer that uses the rules contained in the grammar to decide which hypotheses are acceptable. Only the utterances that can be generated from the grammar may be output.
If an utterance outside of the grammar is spoken and presented to the recognizer it may still be recognized but with low confidence. If the confidence is below a set threshold a NOMATCH will be returned.
The obvious disadvantage of using such a recognizer is that it will not recognize utterances outside the scope of grammar. Such utterances are called Out-of-Grammar utterances. However, a big advantage with this approach is that it will be less prone to misrecognition when an utterance that is spoken has been anticipated and is included in the grammar.
An additional advantage of using a grammar-based recognizer is that most grammars allow for insertion of semantic tags, which allow the grammar to not only define an utterance but also the semantic interpretation of that utterance.
Examples of such a grammar-based speech recognition system would the speech-to-text offerings like Nuance ASR or Lumenvox ASR.
Clearly both types of speech recognition systems have advantages and disadvantages. It hence seems understandable that a combination of both could potentially have the advantages of both while possibly avoiding some disadvantages.
A simple approach would be to combine two different speech recognition systems. One would need to create two speech recognition sessions and split the incoming audio stream so that each session is fed a copy of incoming audio. Those two sessions would process the audio separately and would output separate results that would then need to be combined. This is illustrated below:

The setup as presented above has several disadvantages:
Voicegain platform provides a speech recognition system that combines both types of speech recognition to benefit from the advantages of both. Our system is illustrated in the figure below:

In this system the processing up to the output from the Acoustic model processing is essentially identical to the processing done in systems depicted in the first two figures of this post. However, after that step Voicegain includes a novel Search/Optimization module that uses both grammar and the large vocabulary language model to generate the final recognition results. The end-pointing is performed in a way that is similar to grammar-based recognizer as that seems to make most sense given the use case (but this can be modified). The final recognition result will comprise n-best results from the grammar-based recognition, if the grammar did MATCH, and one or more hypotheses from the large vocabulary recognition.
The application developer may make own decisions as to how to use the recognition result. For example, the confidence value may be used to determine whether the grammar-based result or the large vocabulary result should be used at a given point in the application.
With Voicegain’s release of 1.22.0 , this feature is Generally Available as part of our Recognize API.
An example request using our /asr/recognize/async API looks like this:
As you can see there is just one definition for the incoming audio stream. The grammar section of settings.asr contains two grammar definitions:
In addition to being available in our STT API and Telephone Bot API the ability to support both gramma-based and large vocabulary recognition at the same time is supported via the MRCP interface. For example, from VXML you can pass both GRXML grammar and builtin:speech/transcribe grammar and you will receive both GRXML result and large vocabulary result.
If you are building an Intelligent Voice Assistant, Voice Bot, Speech IVR Application or any other application that could benefit from this feature, please contact us via (email info@voicegain.ai) to engage in a more in-depth discussion.

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices