
Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
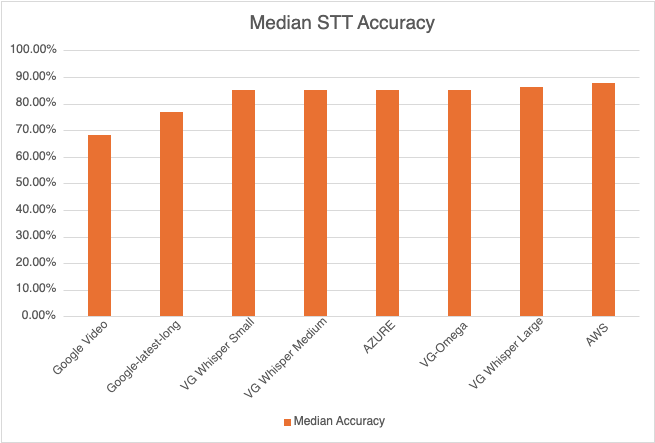
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

Countryside Bible Church has been using VoiceGain platform for real-time transcription since September 2018 (when our platform was still in alpha).
In August 2018 one of our employees was approached by staff at CBC with a question about a software that would allow a deaf person to follow sermons live via transcription. One of the members at CBC is both hearing and vision impaired and cannot easily follow sign language; however, she can read large font on a computer screen from close by.
In August, Voicegain just started alpha tests of the platform, so his response was that indeed he knew such software and it was Voicegain. At that time, our testing was focusing on IVR use cases, so we still needed a few weeks to polish the transcription APIs and develop a web app that could consume the transcript stream (via websocket) and present it as scrolling text in a browser.
To improve recognition, we used about 200 hours of previously transcribed sermons from CBC to adapt our Acoustic DNN Model. Additionally, we created a specific CBC Language Model, by adding a corpus of text from several Bible translation, various transcribed sermons, list of CBC staff names, etc.
As far as the input audio is concerned, initially, we were streaming audio using a standard RTP protocol from ffmpeg tool. We had some issues with a reliability of raw RTP, so later we switched to a custom Java client that sends the audio using a proprietary protocol. The client runs as a daemon on a small Raspberry Pi device.

CBC audio-visual team has been running real-time transcription using our platform since September 2018, pretty much ever Sunday. You can see an example of the transcription in action in the video below
Current plans for the transcription service is to integrate it into CBC website and to make it available together with streamed video. This will allow hearing impaired to follow the services at home via streaming. For now, the transcription text will be presented as an embedded web page element under the embedded video.
Because the streamed video is more than 30 seconds delayed w.r.t. the real-time, we will be feeding the audio simultaneously to two ASR engines, one optimized for real-time response, and one optimized for accuracy. This is easy, because Voicegain Web API provides methods that allow for attaching two ASR sessions to a single audio stream. Each session, can in turn feed its own websocket stream. By accessing the appropriate websocket stream, web UI can display either the real-time of delayed transcript.
Because of their Terms of Use, we cannot provide direct results for any of the major ASR engines, but you can download the audio linked below, as well as the corresponding exact Transcripts and run comparison tests on a recognizer of your choice. Note that Voicegain ASR does ignore most of duplicated words that are in audio, that is why the transcript does have those duplicates removed.
The audio is Copyright of Countryside Bible Church and transcripts are Copyright of Voicegain.
1. God's Plan for Human History (Part 2)
Tom Pennington | Daniel 2 | 2018-11-04 PM
55 minutes 13 seconds, 7475 words
Audio Transcript VoiceGain Output
Accuracy: 1.08% character error rate
Note: Voicegain output is formatted to match Transcript. Normally it also includes timing information. This specific output was obtained on 4/30/19 from real-time recognizer which has slightly lower accuracy compared to off-line recognizer.

You can stream audio for Voicegain transcription API from any computer, but sometimes it is handy to have a dedicated inexpensive device just for this task. Below we relay experiences of one of our customers in using a Raspbery Pi to stream audio for real-time transcription. It replaced a Mac Mini which was initially used for that purpose. Using Pi had two benefits: a) obviously the cost, and b) it is less likely than Mac Mini to be "hijacked" for other purposes.
Voicegain Audio Streaming Daemon requires very little as far as computing resources, so in even a Raspberry Pi Zero is sufficient ; however, we recommend using Raspberry Pi 3 B+ mainly because it has on-board 1Gbps wired Ethernet port. WiFi connections are more likely to have problems with streaming using UDP protocol.
Here is a list of all hardware used in the project (with amazon prices (as of July 2019)):
All the components added up to a total of $101.97. The reason why a mini monitor and a mini keyboard were included is that they make it more convenient to control the device while it is in the audio rack. For example, the alsa audio mixer can be easily adjusted this way, while at the same time monitoring the level of the audio via headphones.
Raspberry PI running AudioDaemon
The device is running standard Raspbian which can easily be installed from an image using e.g. balenaEtcher. After base install, the following was needed to get things running:
Here are some lessons learned from using this setup over the past 6 months:

The team behind VoiceGain has more than 12 years experience of using Automated Speech Recognition in real wold - developing and hosting complete IVR systems for large enterprises.
We started of as Resolvity, Inc., back in 2005. We built our own IVR Dialog platform, utilizing AI to guide the dialog and to improve the recognition results from commercial ASR engines.
The Resolvity Dialog platform, had some advanced AI modules. For example:
Starting from 2007 we were building complete IVR applications for Customer Support and hosting them on our servers in data centers. We build a Customer Solutions team that interacted with our customers ensuring that the IVR applications were always up to date and an Operations team that ensured that we ran the IVRs 24/7 with very high SLAs.
Resolvity Dialog Platform had a set of tools available that allowed us to analyze speech recognition accuracy in high detail and also allowed us to tune various ASR parameters (thresholds, grammars).
Moreover, because that platform was ASR-engine agnostic, we were able to see how a number of ASR engines from various brands performed in real life.

In 2012-2013 Resolvity built a complete low-cost Cloud PBX platform on top of Open Source projects. We launched it for the India market under the brand name VoiceGain. The platform was providing complete end-to-end PBX+IVR functionality.
The version that we used in prod supported only DTMF, but we also had a functional ASR version. However, at that time it was built using conventional ASR technologies (GMM+HMM) and we found that training it for new languages presented quite a bit of challenges.
VoiceGain was growing quite fast. We had presence in data centers in Bangalore and Mumbai. We were able to provision both landline and mobile numbers for our PBX+IVR customers. Eventually, although our technology was performing quite well, we found it expensive to run a very hands-on business in India from the USA and sold our India operations.
When the combination of hardware and AI developments made Deep Neural Networks possible, we decided to start working on our own DNN Speech Recognizer, initially with the goal to augment the results from the ASR engines that we used in our IVRs. Very quickly we noticed that with our new customized ASR used for IVR tasks we could achieve results better than with the commercial ASRs. We were able to confirm this by running comparison tests across data sets containing thousands of examples. The key to higher accuracy was ability to customize the ASR Acoustic Models to the specific IVR domain and user population.
Great results with augmented recognition lead us to launch a full scale effort to build a complete ASR platform, again under Voicegain (.ai) brand name, that would allow for easy model customization and be easy to use in IVR applications.
From our IVR experience we knew that large enterprise IVR users are (a) very price sensitive plus (b) require tight security compliance, that is why from day 1 we also worked on making the Voicegain platform deployable on the Edge.

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices