

Products
AI Voice Agent Platform
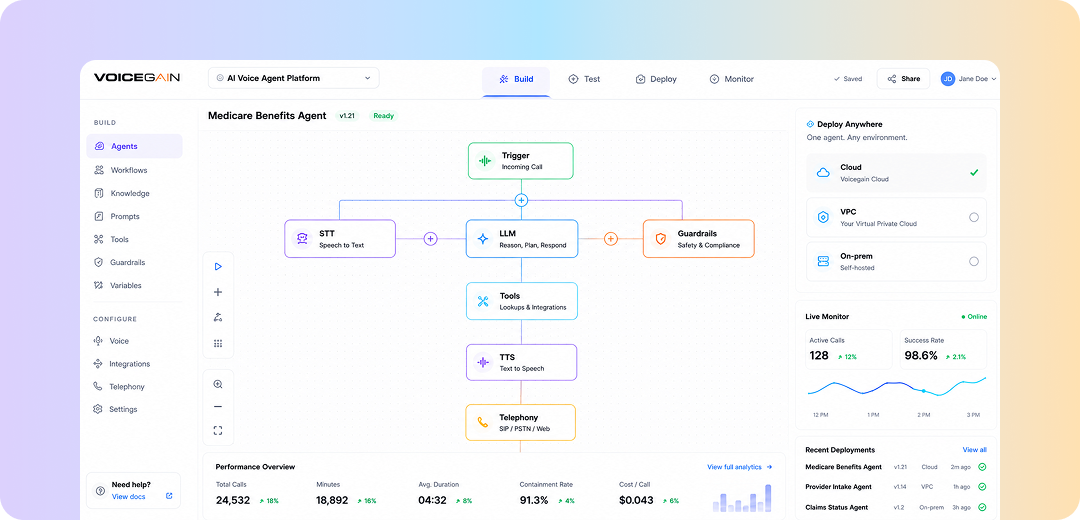
Build LLM-powered AI Voice Agents
Explore more →
MRCP ASR
ASR for VoiceXML IVR Platforms
Explore more →

Developers
APIs, SDKs, Docs & Pricing
Explore more →

By Industry
Help
Documentation
↗Implementation guides
Status Page
↗System health & uptime
Support
↗Get help from the team
Built to fit your stack.
The Platform is API-first — bring the models and telephony you already run, and Voicegain handles the voice layer in between.
Model-agnostic by design — pair the voice layer with the LLM you trust, and swap models without rebuilding your agent.
Integrate with the Voice Infrastructure you already use — your SBC or CCaaS Platform.
Wire agents into your systems with developer-first APIs and real-time events for every call.
Build your own
AI Voice Agent
Meet the Voicegain AI Voice Agent Platform. Works with your LLM & System Prompts. We handle the Voice Infra - the SIP Stack, streaming STT and TTS models. Use as a SaaS Service. Deploy in your VPC or your datacenter.
Trusted by companies building amazing voice AI products






